Service Templates and Service Chassis
managing the cost of microservice plumbing
September 25, 2020
As engineering organizations move towards smaller services and more autonomous teams, it’s common to run into situations where teams are duplicating effort on “table stakes” platform functionality. Rather than spending time solving business problems, engineers waste that time building the same basic technical plumbing multiple times, using inconsistent approaches.
Engineering organizations can avoid this waste by creating a Service Chassis - an org-specific service runtime which provides the base platform functionality that each service needs. In addition, Service Templates can be used to help teams easily adopt this shared Service Chassis when creating new services. In this article we’ll explore these ideas of Service Chassis and Service Templates, and briefly look at how they relate to the increasingly popular Service Mesh concept.
Small services, shared plumbing
Today, many engineering organizations are operating as a collection of autonomous, cross-functional teams, and many of those teams are building microservices. Together, these two trends - autonomous teams and microservice architectures - lead to a challenge.
Every service needs an amount of technical “plumbing” in its implementation. It needs the ability to retrieve configuration values and secrets. It needs to connect to the data stores, message buses, and other services it depends upon. It needs to emit logs and operational metrics. Teams also need build scripts and CI/CD pipelines that allow each service to be tested, packaged, deployed, and operated.
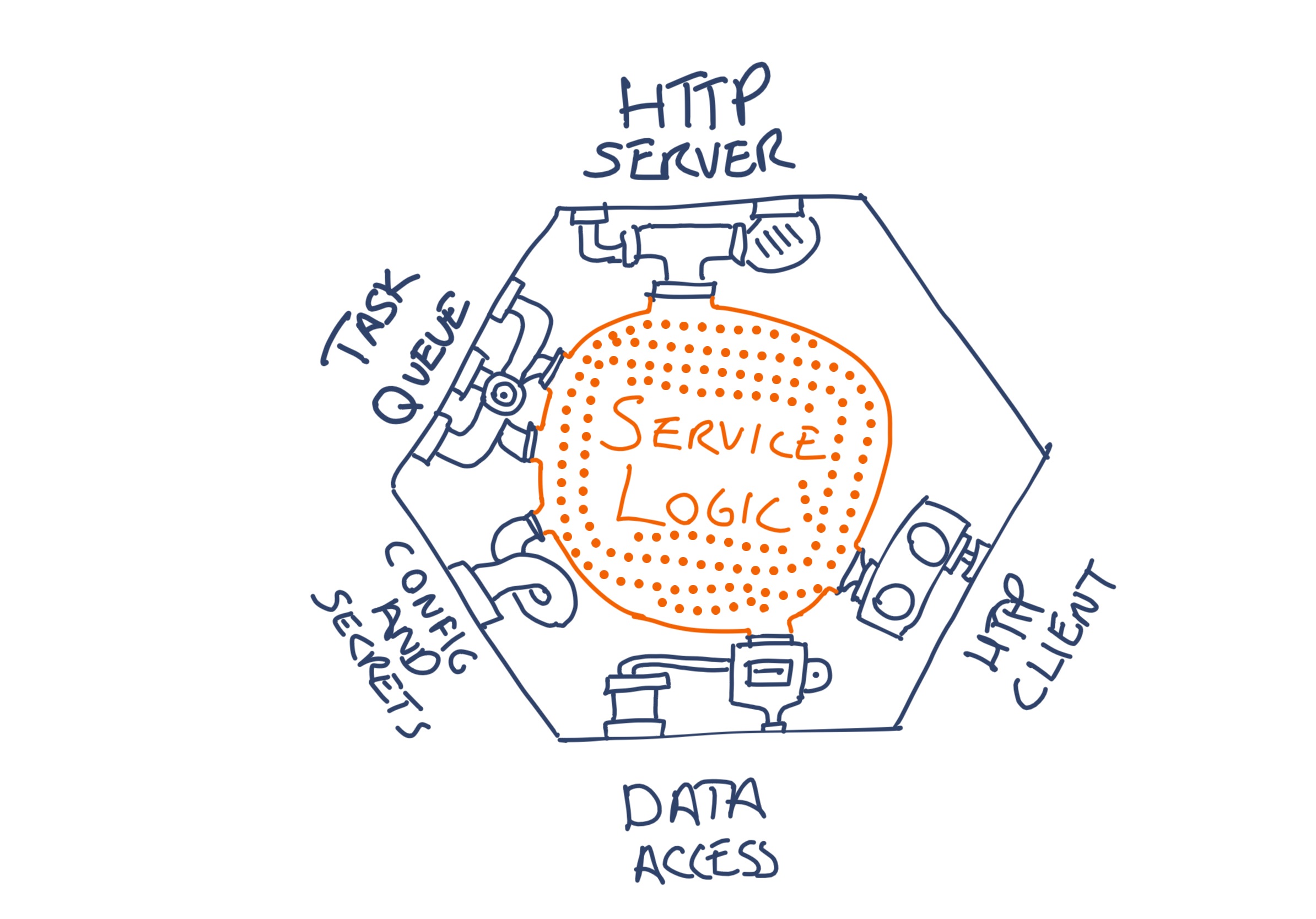
a small service, with all its attendent plumbing
However, when each service is being built by autonomous teams, working independently, there is a tendency for these basic technical capabilities to be re-implemented by each team. The Green team have their implementation for service discovery, the Yellow team have a different implementation, and the Red team have a third, even if they’re all using the same tech stack.
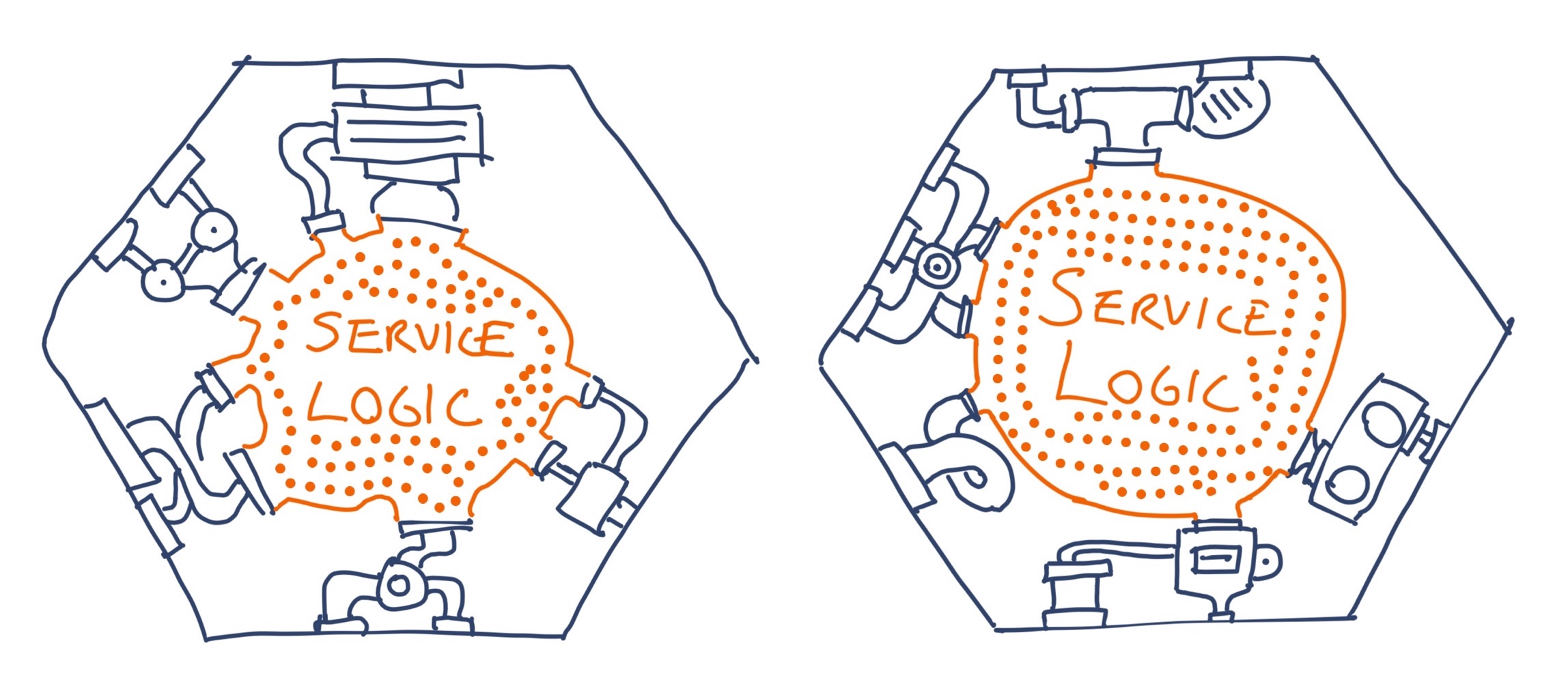
two services, built by two different teams, each with different implementations of the same plumbing
Each team is wasting time on boring technical glue - time which would be much better spent on building product functionality. The question is, how do we avoid each team re-inventing the same wheel, while still empowering those teams with autonomy?
One fairly common solution is to establish a Service Template - a “Hello, World” service which includes a standard implementation of all the platform plumbing that each service needs. When a team needs to create a new service they start with a copy of this Service Template. This means that all such services inherit a common and consistent implementation of platform capabilities. However, teams are still able work independently on their services after they’ve been stamped out from the template.
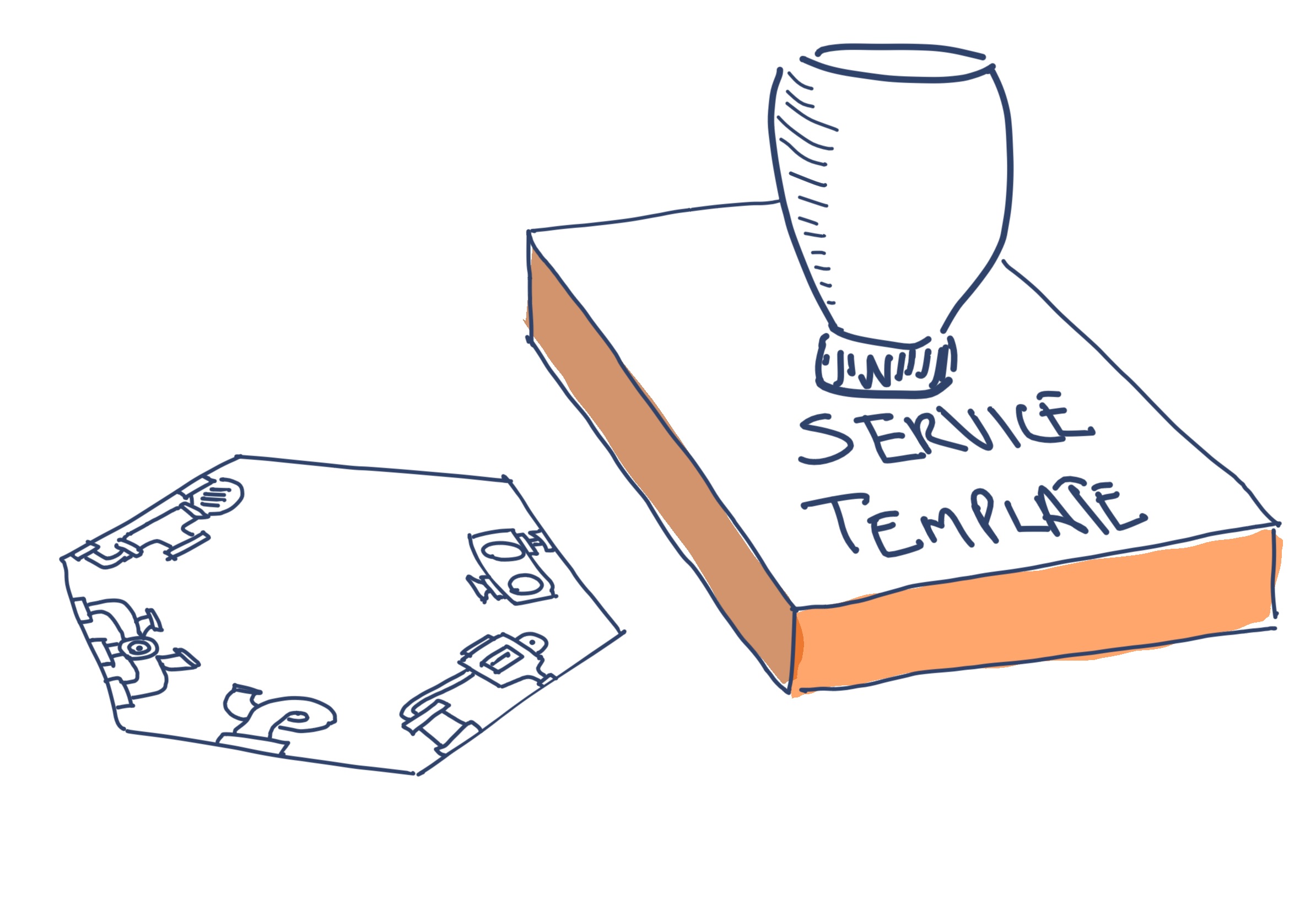
a service template which can be used to stamp out a new service, with standardized plumbing ready to go
What constitutes “plumbing”?
What do I mean by “plumbing” or “technical underpinnings”? It’s the code you write which isn’t specific to the actual purpose of a service, but which is necessary in order to operate your software in production. Code which does things like:
- establishing connectivity to infrastructure such as databases, message buses, event queues, and so on
- figuring out the URL for a dependent service (i.e. service discovery)
- logging, instrumentation and observability for your service
- retrieving configuration values
- determining the state of a feature flag
- defining the contents and boot procedure for your service’s container
- and so on…
Basically, plumbing is any code or configuration that serves the technical aspects of operating a service, rather than the business domain of your service. All of this plumbing is necessary, but it’s unrelated to the product features your service is built to provide. It’s accidental complexity, rather than essential complexity.
In contrast, business logic is the code which implements that actual valuable functionality of a service. For a Shopping Cart service it’s the code which keeps track of what products are in a cart. For a Shipping service it’s the code which figures out which shipping options are applicable for a given set of purchased products, and how much each shipping option would cost.
In Hexagonal Architecture terms, the plumbing is all the “ports and adapters” stuff at the edges of the service’s implementation, while the business logic lives in the chewy central domain.
The value of shared plumbing
There are a variety of benefits in re-using this technical plumbing across different services built by different teams.
Reduce the variable costs of microservices
Basing a new service off of an existing set of shared plumbing allows a team to get straight to building that valuable business functionality without wasting time wiring up the underlying technology.
This is particularly valuable when working in a microservices architecture, for two distinct reasons. Firsly, microservices have relatively more plumbing code, since you have a large number of distinct services and each service needs its own plumbing. Secondly, a microservices architecture is a complex distributed system, and has more complex operational requirements. Each service needs to support capabilities like distributed tracing, service discovery, healthchecks, and so on. All of these capabilities require additional code and/or configuration.
Phil Calçado has an interesting economics analogy. You can think of the plumbing that each microservice requires as an additional, variable cost to running a microservice architecture - a team must pay this cost for every new service. By sharing and re-using this plumbing implementation we can convert that variable cost to a single fixed cost.
Make arbitrary decisions consistent
We’ve already seen that when we lack a standard implementation for a piece of technical infrastructure it’s likely that multiple incompatible implementations will emerge. For example, one team’s services might all listen on port 3000 while another team’s services are all listening on port 8080. The decision of which port to listen on is arbitrary - there isn’t a wrong or right decision. If we fix these arbitrary decisions up front - by baking them into a shared implementation - we can avoid a potential bikeshedding discussion, and reduce each team’s cognitive load. When we deliver a bikeshed pre-painted, product engineers can focus on more interesting things.
Beyond avoiding some uninteresting decisions, a consistent approach also allows the ecosystem supporting our services to make more assumptions and be less complex. If every service listens on the same port (because that decision is baked into shared plumbing) then the infrastructure to deploy services and route traffic to those services can become slightly simpler. The same logic applies to a myriad of other small decisions, such as how service configuration is injected, how logging is performed, and so on.
Governance as Code
The technical foundations of a service are a place with a great amount of leverage. It can influence how every service in your architecture is built and operated. You can apply some gentle architectural governance by giving teams an easy, out-of-the-box setup which also aligns with how you’d like services to behave.
This approach can work well in organizations that lean towards autonomy and resist top-down architectural guidance. Rather than mandating a certain approach, you instead just make it easier for things to be done that way. This comes back to that economic metaphor of Phil Calçado’s. We reduce the transaction costs of taking the preferred approach - make it cheaper to do the right thing - and things will naturally move in that direction. A free, pre-packaged implementation of a service’s basic technical underpinnings reduces the friction in taking the preferred approach to building and running services.
Service Templates
Teams often begin sharing technical plumbing between services in a fairly ad-hoc way. An engineer tasked with creating a new service will literally copy-paste some of the plumbing code from another service. More often than not, after doing this a few times a team will create a shared example service as the official place to copy-paste from - a Service Template. This is a simple working “Hello, World” service, including whatever build-and-deploy configuration is appropriate to keep within that repo (a CI/CD configuration, a Dockerfile, and so on). When a team needs to create a new service they clone that codebase and then run a templating script which renames various variables and configuration values to match the new service’s name. Once that script has run the new service is ready for feature development.
Plumbing Drift
This service cloning approach delivers a lot of what we’re looking for in shared plumbing, but it comes with a major downside: plumbing drift. After generating a new service using a template, that service loses its connection to the common implementation. Any “up-stream” changes which are made to the code in the Service Template will not appear in services generated from that template. Likewise, any improvements made in one of the generated services will not make it back up-stream to the shared implementation unless an engineer takes the time to port that change back into the template as well. Because of this, our services’ plumbing implementations will drift apart.
Over time, this drift leads to an ecosystem of “snowflake services”, where each service does things a slightly different way. This situation is manageable when your architecture consists of a handful of services, but as the number of distinct services grows, this lack of consistency can seriously hamper any infrastructure initiatives which cut across a large set of services.
We can try and reduce this drift by making it easier to port changes up- and down-stream. For example, when stamping out a new service from a template we can preserve the connection between the two by making the new service a fork of the template repo, and preserving the template repo as a remote. This means that, with sufficient git-fu, you can push and pull commits from one repo to the other, rather than being reduced to manually copying and pasting code snippets.
However, even with version control tooling working in your favor, the cost of keeping a service and its template in sync is usually too high, and eventually they wil drift further apart and attempts to keep them in sync will be abandoned.
From copy-pasta to chassis
Happily, there’s a solution to this problem of plumbing drift. Shared plumbing code is just that - code. If an engineer finds themself copy-pasting the same chunk of code over and over again, what do they do? They extract that code into a shared library. That same approach can be applied to the plumbing in a Service Template - we can extract it into a set of packaged libraries. We can then pull in those shared libraries to form the basis of each new service we create. Together, they form what’s known as a Service Chassis - an opinionated service runtime framework focused specifically on your organization’s technical platform.
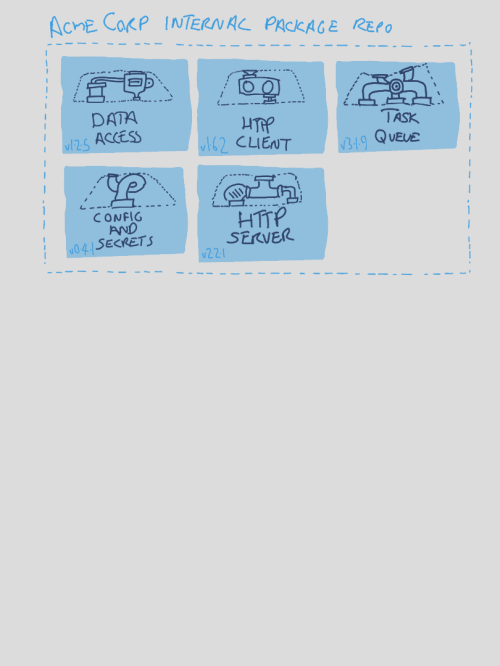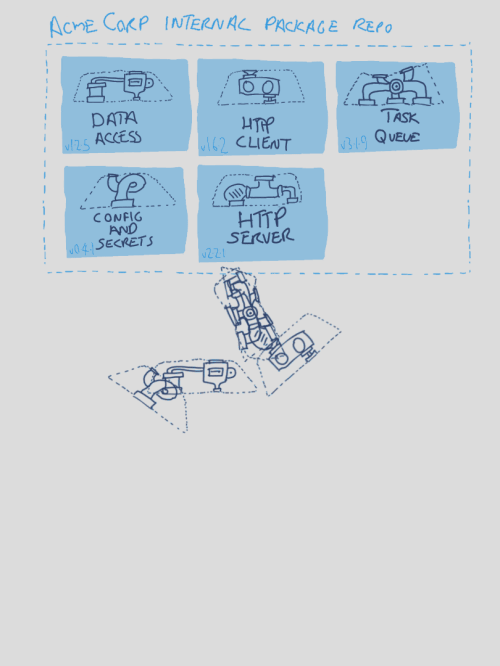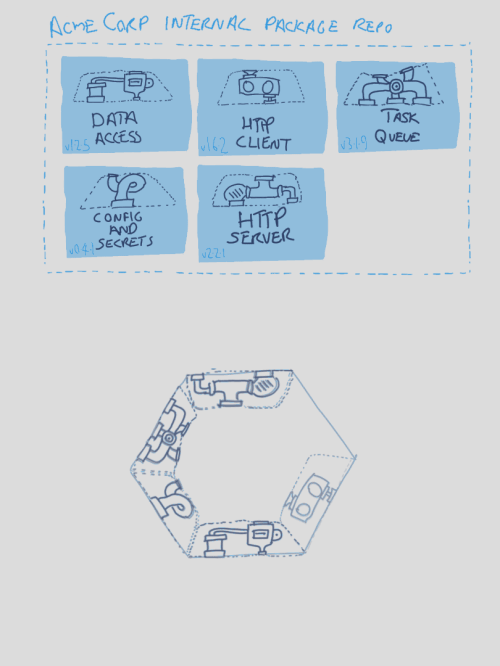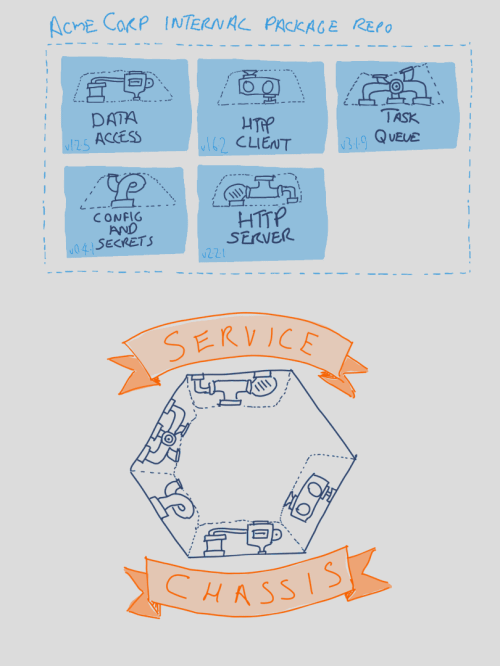
a Service Chassis assembled from a set of shared internal libraries
reduce drift by managing dependencies
This approach significantly reduces the risk of plumbing drift by providing a defined upgrade path for our shared plumbing. Whenever we have an improvement for our shared plumbing we make that change in the appropriate internal library, publish out a new version, and then use dependency management to pull that updated version into each service.
This still requires some work - keeping our service’s code dependencies up to date always does - but it’s a much more manageable option than manually syncing code changes from a template into each service’s codebase. Platform teams also have the option of using dependency management tooling to do fancy things like identifying services which are using out-dated plumbing, so that these services can be targeted for upgrade support.
it’s an ‘and’, not an ‘or’
It’s important to note that a Service Chassis isn’t a replacement for a Service Template. In fact, they complement each other together nicely. An organization can continue to use a Service Template as a basis for creating new services, but rather than containing a bunch of plumbing code, the template instead includes an assembly of the latest Service Chassis library versions.
Besides, a Service Template should include more than just the runtime implementation that a Service Chassis provides. A good template also provides a standard approach for testing, building and deploying each service - including things like build scripts, Dockerfiles, CI/CD pipeline configuration, and so on.
What about Service Meshes
You might be wondering how a Service Mesh fits in here. A Service Mesh does occupy a similar space to Service Chassis - both are a mechanism for providing shared runtime platform capabilities within a microservice architecture. We won’t spend much time here looking at Service Meshes, but I would like to point out that Chassis and Meshes are complimentary, to some extent.
The sweet spot for Service Meshes is in shared network-level platform capabilities - service discovery, request routing, distributed tracing, things like that. However, there are a lot of other beneficial platform capabilities which a Service Mesh can’t easily provide: configuration management, feature flagging, non-technical analytics, authz and authn, and more. While it may be possible to provide some of these capabilities via a sidecar-type approach (Netflix’s prana is an example of this) the value of doing so is questionable. The benefit of a sidecar is that it can be shared across tech stacks, but the drawback is that your service logic has to make inter-process calls to access these platform capabilities, rather than a simple function call into a Service Chassis library.
I would say that most architectures that are using a Service Mesh would still benefit from a Service Chassis, even if it’s a fairly “thin” chassis which primarily adds some developer ergonomics to the capabilities provided by that Service Mesh.
Succeeding with shared plumbing
The idea of establishing common platform code for use by many services is fairly common, and many organizations adopting microservices end up adopting the approaches we’ve explored in this article.
However, some organizations have more success in this area than others. Let’s look at what you can do to ensure success, and what you should avoid.
It’s all about adoption
You get the most benefit from Service Templates and Service Chassis when they’re widely (if not universally) adopted by teams in your organization. The best way to ensure that adoption is to think of these things as products. Understand the customer of the product, and make sure the product addresses a pain they are feeling. If you are a platform team, focus on building the template and libraries that your customers want, not the ones you want.
You’ll have much more success driving adoption of a small, complete product than a grandious framework which has rough edges and is hard to use. Get some success and adoption with a simple library that does a couple of valuable things well, and then start layering in support for additional features.
It can make sense to focus initially on one or two teams as early adopters, in order to get fast feedback. However, you should aim to get adoption from a broader variety of teams as early as possible, to avoid accidentally specializing on the needs of one particular type of team.
Reduce the friction
Since your goal is to gain broad adoption of something that reduces transaction costs, it pays to make your Service Templates and Service Chassis as simple and low-friction to use as possible. That means investing a good amount of effort on documention, and keeping any manual steps to an absolute minimum.
For a non-trivial Service Template, consider using a code-gen tool to automate the creation of a new service with appropriate naming of configuration values, files, class names, and so on, rather than expecting your users to do a fiddly search-and-replace. Giter8 is one tool which is specifically designed for this task. That said, a simple shell script with some well-crafted sed and awk commands can get you pretty far.
Ideally, an engineer can run a single command (or press a single button in a UI) to generate a new “Hello, World” service, along with the attendant CD pipelines, and that new service is ready to be deployed and operated within your production environment. The investment required to achieve that level of automation is likely to be prohibitively expensive, but that “one-click” goal is useful as a north star.
Follow the principle of not asking your users to think too much. A semi-automated solution is better than nothing. Creating a well-defined checklist of manual steps to perform when creating a new service is better than relying entirely on tribal knowledge. Writing a script which files an ops ticket that’s then manually fulfilled is better than some documentation that says “ping someone in Ops who can set you up a database”.
For Service Chassis, look for opportunities to delight your customers by magically making something that’s painful or tedious disappear. For example, your chassis can provide a healthcheck endpoint which comes pre-wired with connectivity checks for the service’s dependencies (databases, message busses, and so on). Or perhaps your chassis provides database connectivity and API clients that automatically integrate with your distributed tracing system, or a metrics API that automatically includes contextual information like environment, service version, and feature flag state. In short, make the Service Chassis a compelling product that teams use because they want to, rather than because they’re told they have to.
Make it easy to do the right thing
Microservices place a much higher burden on individual teams when it comes to infrastructure and operational support. In this article we’ve seen that Service Templates and Service Chassis reduce some of that accidental complexity and allow product teams to focus on producing business values. In addition, these approaches provide lightweight architectural governance, encouraging teams to follow a consistent path by making it the clear and easy path. Finally, we’ve seen that we only realize the full value of this type of shared plumbing when it gains broad adoption, and adopting a product mindset is what will make that happen.
Get in touch
If you’re using these approaches, I’d love to hear what’s working well and where you’re running into challenges. If you’re looking to take it to the next level with Service Templates and Service Chassis at your organization, I can help with that too! Let’s talk.
Other resources
I believe Chris Richardson coined the term Microservice Chassis, although his definition describes a more generic chassis (i.e. Spring Boot) rather than the org-specific framework that I describe here.
Sam Newman discusses Governance Through Code generally, and Tailored Service Templates specifically, in his excellent Building Microservices book.
As I mentioned within this article, Phil Calçado presented a really interesting take on driving microservice adoption based on economic thinking. Sadly the video was lost at some point, but slides are here and happily, InfoQ also produced a nice summary of the talk.
Monzo is a engineering organization that has really gone all-in on microservices. While I’m quite skeptical regarding how far they’ve taking things (~1600 services and counting!), this presentation provides an interesting description of an advanced application of the ideas in this article.
Acknowledgements
Many thanks for Phil Calçado and Sam Newman for reviewing an earlier version of this article and providing a lot of valuable insights.