Patterns of cross-team collaboration
June 17, 2021
Almost every company feels pain when it comes to organizing work that spans multiple teams.
How do we get the appropriate work into each team’s backlog, and how does each team juggle the competing priorities that cross-team initiatives demand? It’s hard! What’s more, for a scaled-up engineering organization any meaningful product change will require this type of cross-team coordination - anything that’s impactful enough to truly improve a user’s experience requires coordinated work across multiple engineering teams, and that coordination is hard.
What’s to be done? It can sometimes seem that the concept of code ownership is part of the problem. If every team could simply contribute to every codebase, then we wouldn’t have to do as much cross-team coordination! Right? Well, perhaps, but it turns out that diffuse or shared ownership can lead to a different set of challenges, mostly centered around the long-term technical health of our systems.
As with most non-trivial problems, there isn’t a single neat solution. But there are some approaches which can reduce the pain. In this post we’ll explore some patterns which make it easier for one team to contribute to another team’s codebase. We’ll also discover some patterns which allow us to sidestep the need for cross-team collaboration entirely.
This is likely the first in a series of posts on this topic. If you enjoy this one and would like more, please feel free to send me a note of encouragement, or sign up at the bottom of this page for notifications on future posts.
Code ownership patterns
We’ll get started by looking at some patterns regarding code ownership - which team owns a given codebase (or area of a codebase).
Before we dive in, let’s get a clear definition around what we mean when we say “codebase”. For the purposes of this discussion, I define a codebase to be the entire set of source code behind a deployable artifact. For many organizations, that equates to a source code repository - all the code for service Foo lives in a git repo called foo-svc, for example. However for organizations that are doing monorepos, a codebase will equate to a subsection of the monorepo. All the code for service Foo lives in the /services/foo directory of a git repo called the-monorepo.
With that definition out of the way, let’s dive into our code ownership patterns. We’ll start with an easy one.
Single Owner
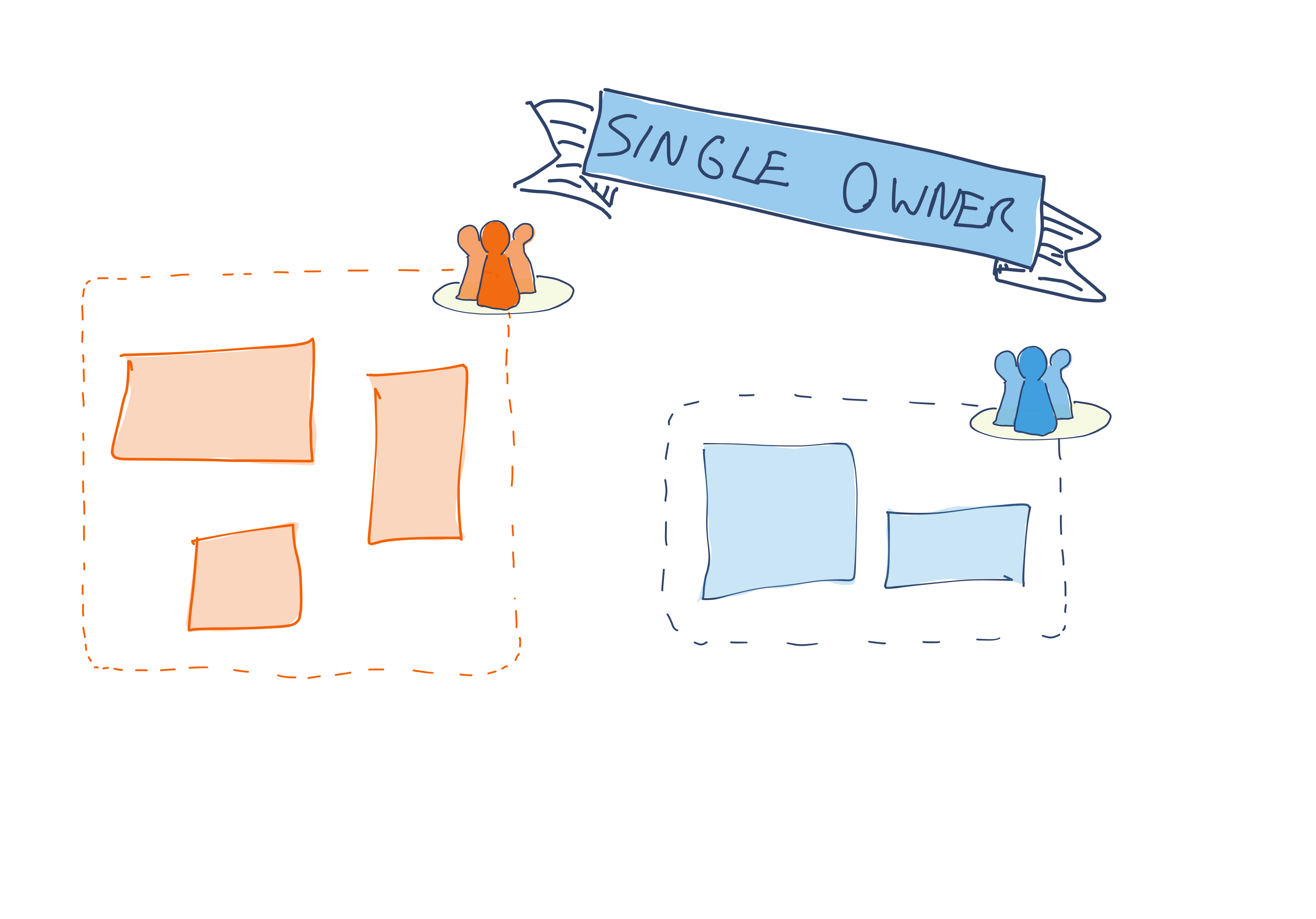
The simplest approach - and one which is more common with today’s trend towards smaller services - is for each codebase in a system to be owned by a single team. A team might own multiple codebases, but each codebase is owned in its entirety by one team.
Orphan codebase
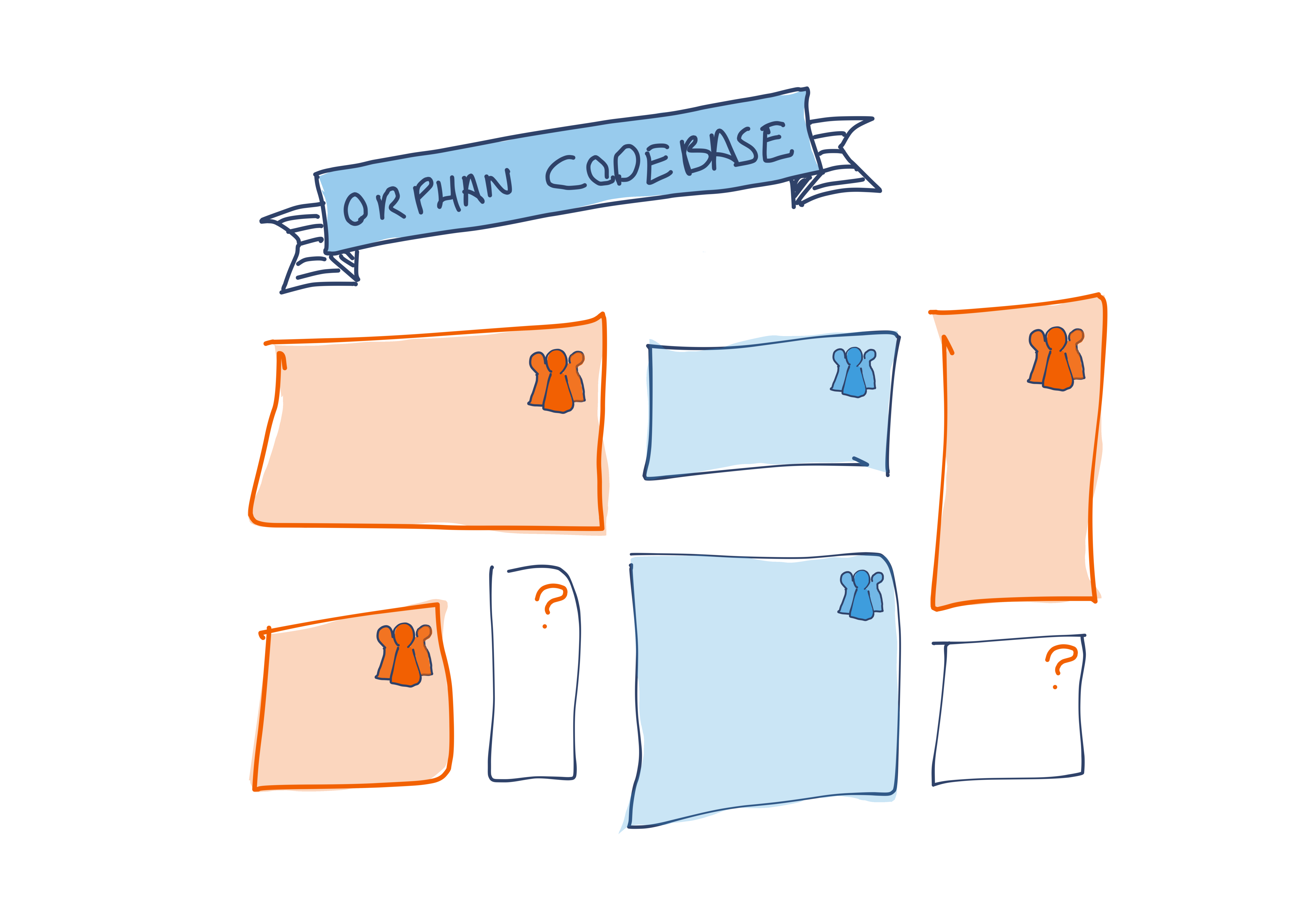
When you are operating a large number of small services, some of those codebases can end up without an owner. Perhaps the team that created them has been disbanded, or the service was a pet project that somehow became an important production dependency for other services. We refer to these codebases without a clear owner as orphan codebases.
Modular Monolith

Often a single system is too large to be managed by a single team. This type of system, which is deployed as a single unit but worked on by multiple teams, is typically referred to as a monolith.
To handle the challenge of multiple teams working in a single monolithic codebase we can define clear internal divisions within that codebase and assign a single owning team for each of those internal components. This gives us a Modular Monolith.
This approach is often associated with large legacy systems, but it’s also commonly seen in large modern mobile applications and single-page web applications. It’s also sometimes used for cases such as centralized repos for infrastructure-as-code, or system configuration.
Tragic Commons
Defining clear ownership boundaries in a shared codebase is hard. Sometimes we cop out and declare that a codebase - or area of a codebase - has “shared ownership”. This usually doesn’t work out well, and translates to “no ownership”.
Diffused ownership means that there are few engineers who have deep expertise in the system. Additionally, since no one feels ownership of the code, engineers working in the system are incentivized to take shortcuts for short-term benefit, which is traded off against a gradual accumulation of long-term tech debt. This anti-pattern is a classic example of a tragedy of the commons.
Code collaboration patterns
Every non-tiny engineering org needs to coordinate work which involves codebases owned by more than one team. Maybe a front-end team needs a change to an API endpoint as part of implementing a new feature. Or perhaps a platform team is rolling out a migration which requires some changes by many product delivery teams - “we’ve released a new version of our shared logging library; can you please update and make these small changes to ensure compatibility”.
When we take a step back, we see that these are all variants of the same challenge - how does a team get changes made in a codebase that they don’t own. Let’s explore some different patterns for one team getting a change into another team’s codebase.
We’ll frame these patterns in terms of a Driving Team - the team which needs a change in a codebase - and an Owning Team - the team which owns that codebase.
File a ticket
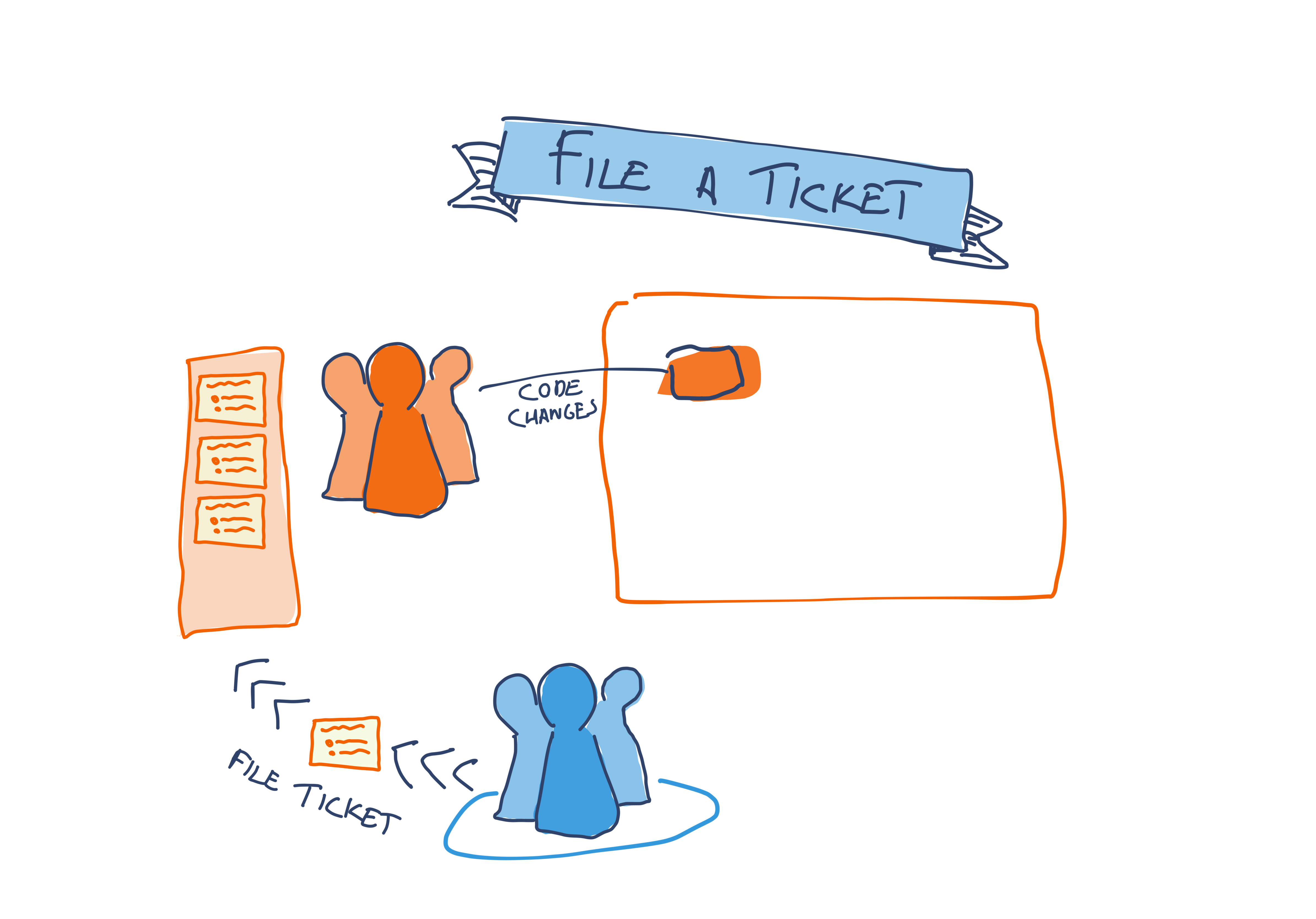
A classic approach to getting a cross-team change made is for the driving team to file a ticket with the owning team. Work gets placed into the owning team’s backlog, who prioritize it against other work.
Internal open-source
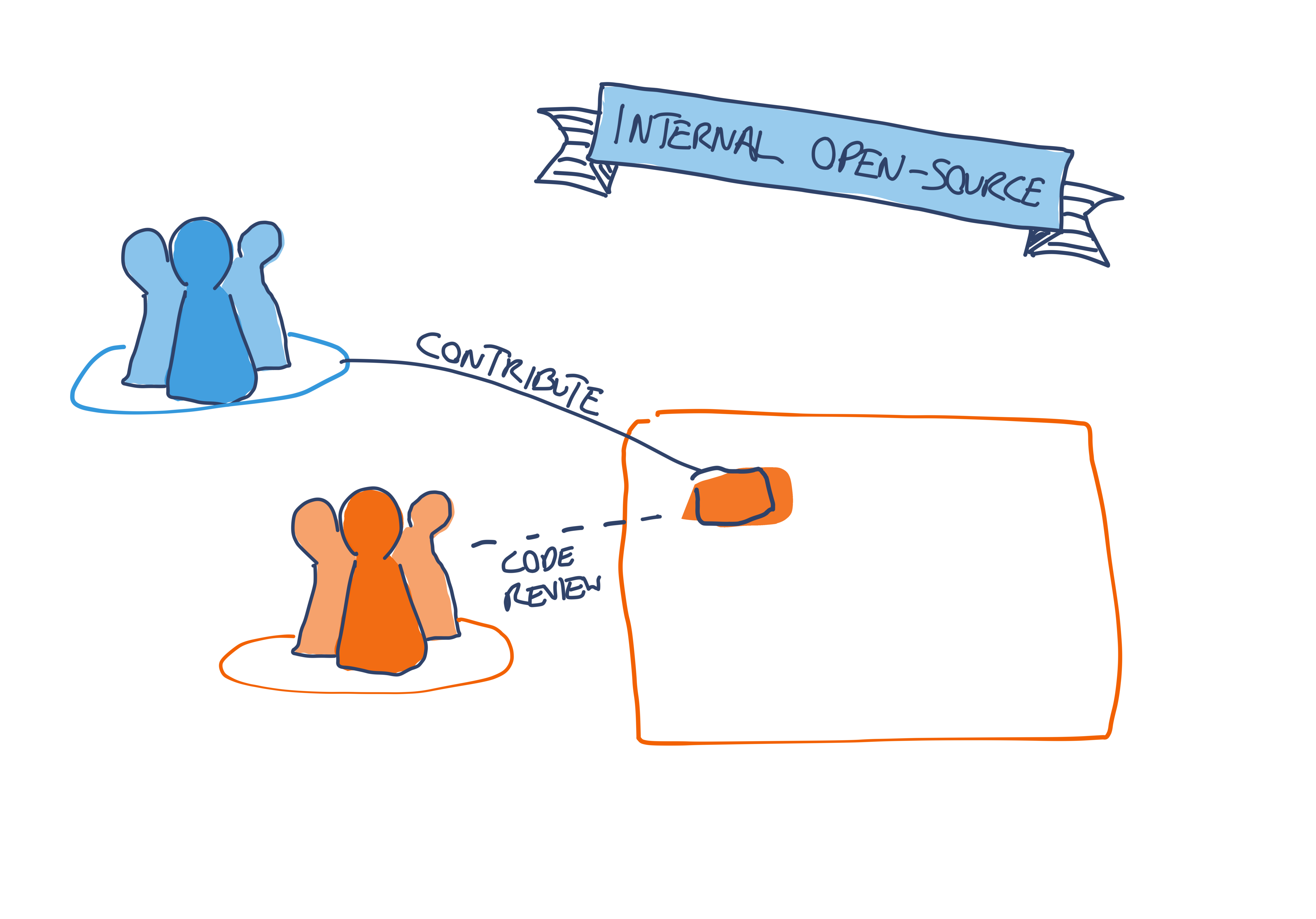
Rather than waiting on the owning team to make a change, what if the driving team could do it themselves? That’s the premise behind internal open-source.
With this approach, it’s the driving team who make the changes to the codebase. They submit pull requests to the owning team, using a process similar to open-source contributions. The owning team act as “maintainers”, reviewing and merging the driving team’s PRs.
Trusted outsider
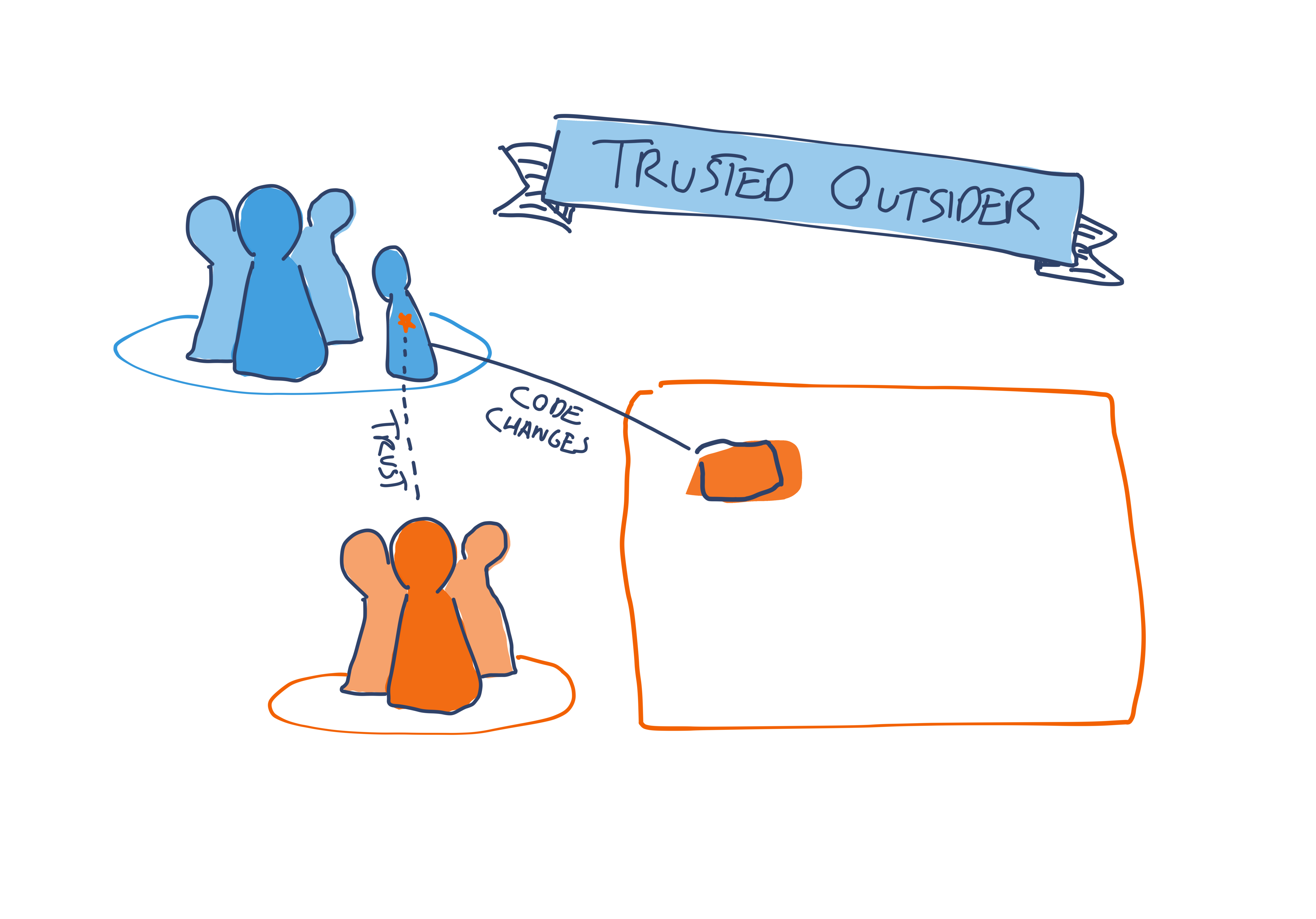
Similar to internal open-source, in this model an engineer from the driving team is empowered to directly change the owning team’s codebase. The difference in this model is that the owning team anoints specific outside engineers as trusted contributors. This is a small set of engineers who understand the codebase and are entrusted with the “commit bit” - the right to make direct contributions to the codebase, often with a less rigorous review process than the internal open-source approach.
Organizations that buy into this pattern often make use of mechanisms such as CODEOWNER files to track who’s trusted to contribute where.
Tour of duty
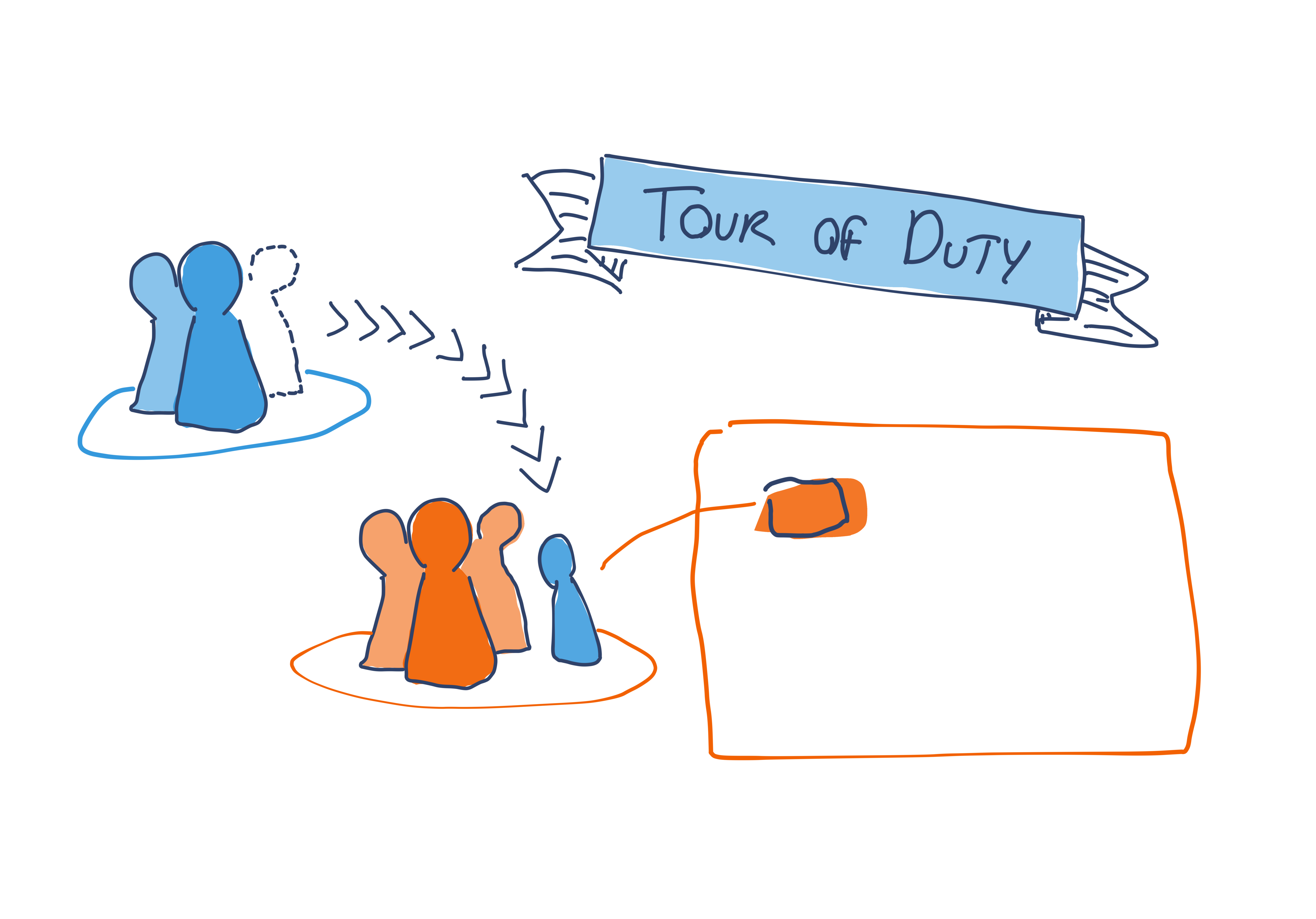
In this model one or more engineers from the driving team are temporarily embedded within the owning team, so that the required changes can be made from within that team. These changes aren’t necessarily all made by embedded engineers. They may also act as subject-matter experts, explaining the context behind the required changes to other engineers on the owning team who in turn help implement those changes.
A tour of duty can be a good way to grow more trusted outsiders who can contribute to the codebase in the future without needing to be fully embedded into the owning team.
Embedded expert
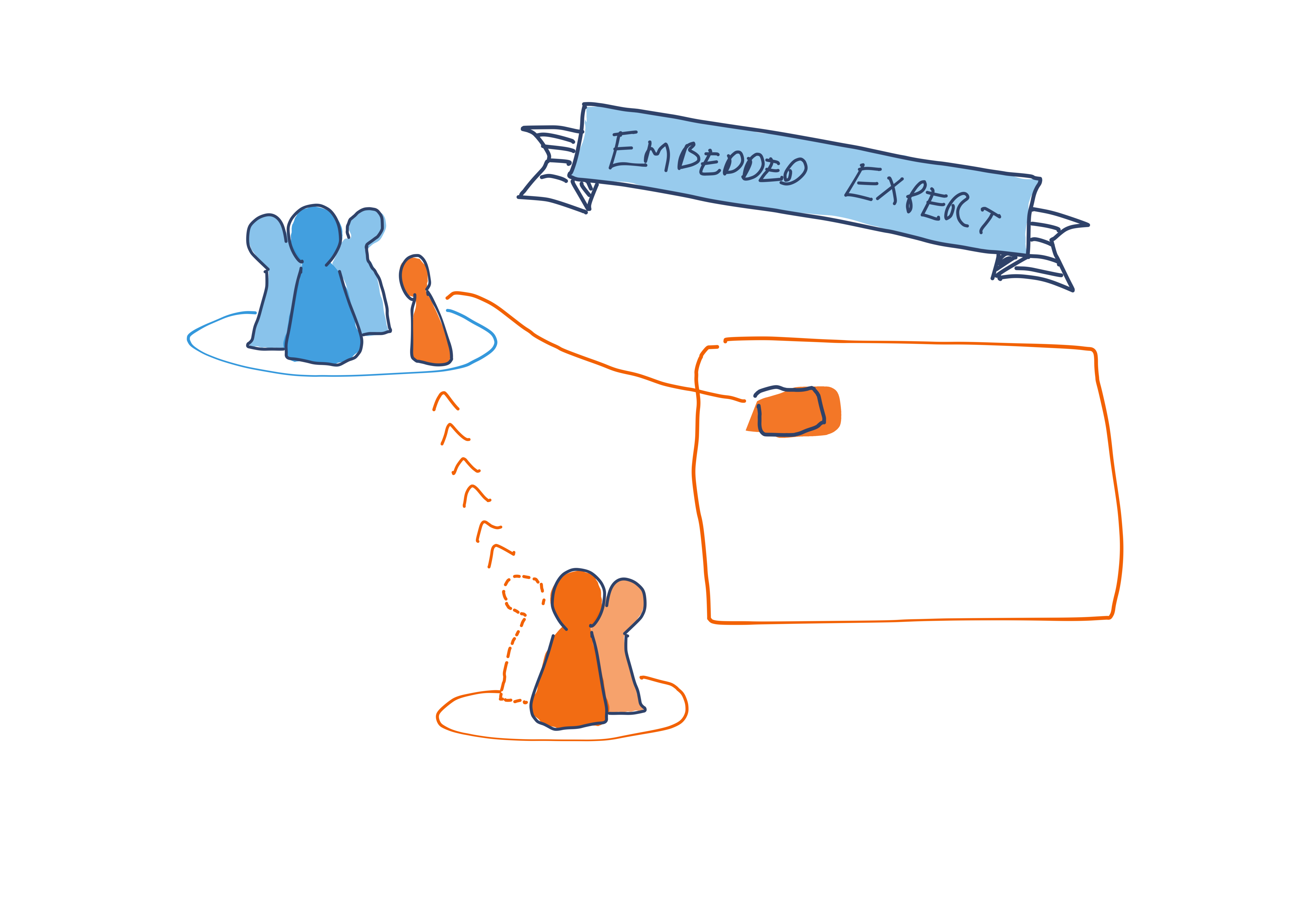
Taking an inverted approach to a tour of duty, we can instead embed an engineer from the owning team into the driving team for some period of time. This allows them to act as a sort of super trusted outsider - directly making changes to the owning team’s codebase while not technically being a member of the owning team.
What’s next
We’ve looked at ways to establish ownership between teams and codebases, and ways for teams to coordinate changes across those codebases. Importantly, we’ve defined a common language for these different approaches.
Stay tuned for future posts which cover when it makes sense to apply which of these patterns, and how that can change over time. I also plan to dissect the interesting differences between product initiatives that require changes to shared services, vs centralized platform initiatives that require changes in product-oriented codebases further up the stack
Acknowledgements
Much credit is due to Nolan Patterson, who helped me refine these patterns over the course of several fun conversations. Thanks to Rogério Chaves for suggesting the Trusted Outsider pattern.