Expand/Contract: making a breaking change without a big bang
December 5, 2023
Adding a new feature to a software system sometimes requires making a breaking change in a database schema or API schema. Deploying such code changes, where the previous version of your software is not compatible with the new version, can be challenging.
The easiest way to roll out a breaking change is in a “big bang” - change both sides of the system all in one go. However, this option requires taking downtime during a deployment, and isn’t possible at all if you don’t have extremely tight control over the timing for deployments (think mobile apps, single-page web apps, or APIs with 3rd party clients).
Happily, there’s a widely accepted way to make a breaking change without needing to stop the world for a big-bang deployment: the Expand/Contract pattern. Mastering this approach is the key to unlocking zero-downtime deployments.
This article will explain Expand/Contract. We’ll walk through an example change to illustrate the limitations of a big bang change, then see how Expand/Contract overcomes those limitations.
safely making a schema change, using Expand/Contract
Stopping the world to make a breaking change
Let’s imagine that we maintain a blogging platform. We want to help bloggers monetize their content by adding a members-only feature, where certain posts are only available to paid subscribers.
Our database schema already has a boolean is_published column which was originally built to allow an author to hide posts that are still in draft. We’ll implement our members-only feature by replacing that boolean with an enum - rather than a post being either published or not, a post will be in one of three “publication states”: draft, members, or public.

replacing is_published with pub_state in BlogPost
As an astute reader, you may have noticed that this is a breaking change to our schema - existing software will break if it tries to use the new schema (the is_published column is missing!) and new software will break if it tries to use the existing schema (the pub_state column is missing!).
For example, let’s say we have one system which writes to the database, and another that reads from the database. If the reader was updated but the writer was not then the two systems would no longer be compatible.
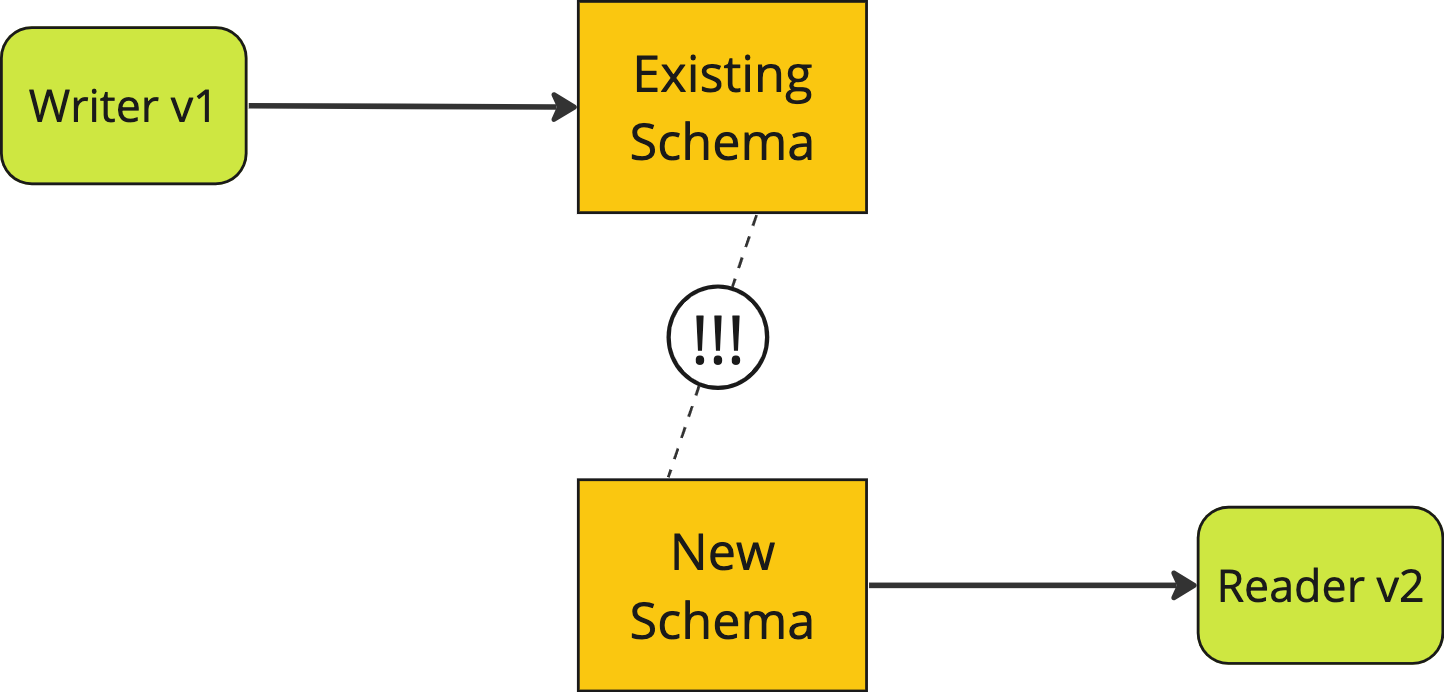
the old writer is incompatible with the new reader
When initially confronted with this incompatibility, we might opt to solve it by updating everything all at once, in a “big bang” deployment:
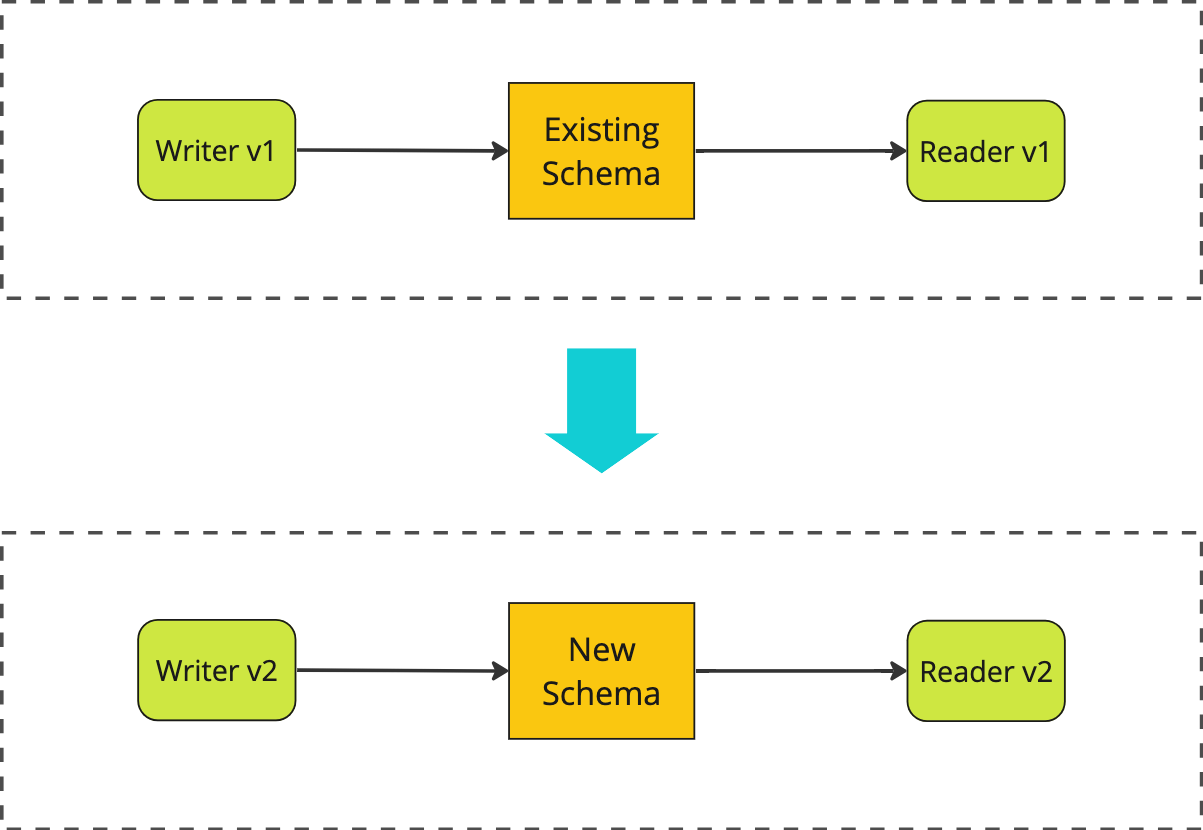
upgrading everything at once in a "big bang" deployment
For this approach to work we would have to perform a “stop-the-world” style deployment where we:
- temporarily shut down access to the system
- migrate the database - updating the schema and backfilling the
pub_statefield for all existing records based on theiris_publishedfield - deploy new versions of both the reader and the writer service
- restore access to the system
This stop-the-world approach works, but it’s fraught with problems.
Firstly, you need stop the world! Taking production downtime for a deployment is less and less acceptable these days, particularly when a data migration pushes out the duration of that downtime.
More importantly, a lot of systems simply don’t have the ability to roll out a change to all parts of the system at once - think mobile apps, single-page web apps, or third-party clients to a public API.
Finally, making all these changes in one go is pretty risky and if anything goes wrong you’re suddenly in a situation where you need to quickly roll back these changes, under pressure, while your production system is down. Oh and that roll back will likely include rolling back that data migration. You tested that the reverse migration worked ahead of time, right???
Expand/Contract to avoid big bangs
So if a stop-the-world big bang deployment isn’t feasible - or even possible - then how do we make this sort of backwards-incompatible change? The solution is to break the deploy down into a series of independent deploys, where each individual change preserves compatibility.
This sequence of changes is often referred to as Expand/Contract, because it involves first Expanding the system so that it support both the old and the new schema, and only once all parts of the system support the new schema do we Contract by removing support for the old schema.
Let’s illustrate how that works in detail, using the blogging example. As a starting point, we have a writer service and a reader service, both talking to a database with our initial schema.
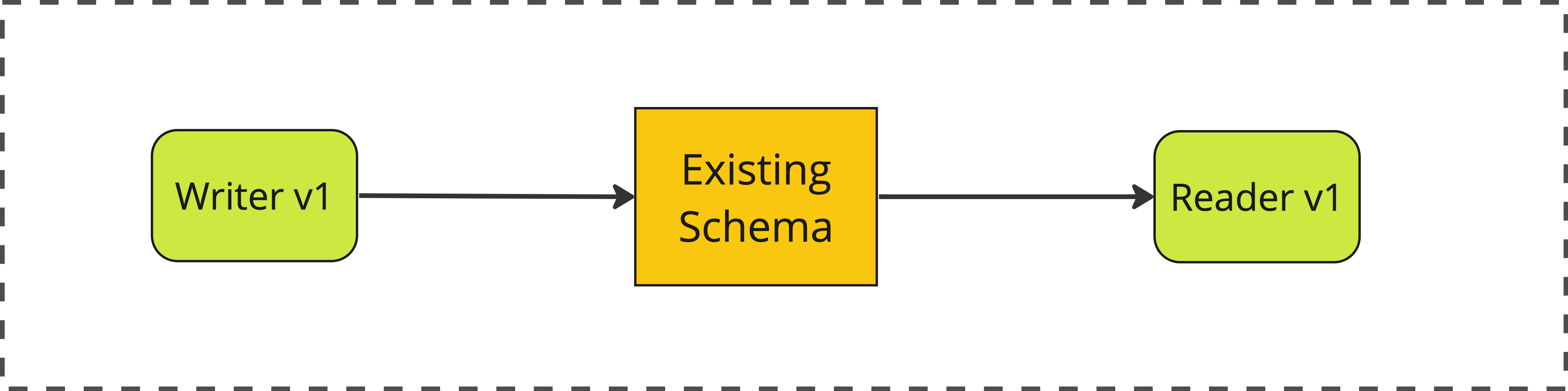
the existing system, before any changes

the existing schema, before any changes
1. Expand
The first change we’ll make is to upgrade our writer service so that it’s writing to both the old AND the new schema. This is referred to as a Dual Write.
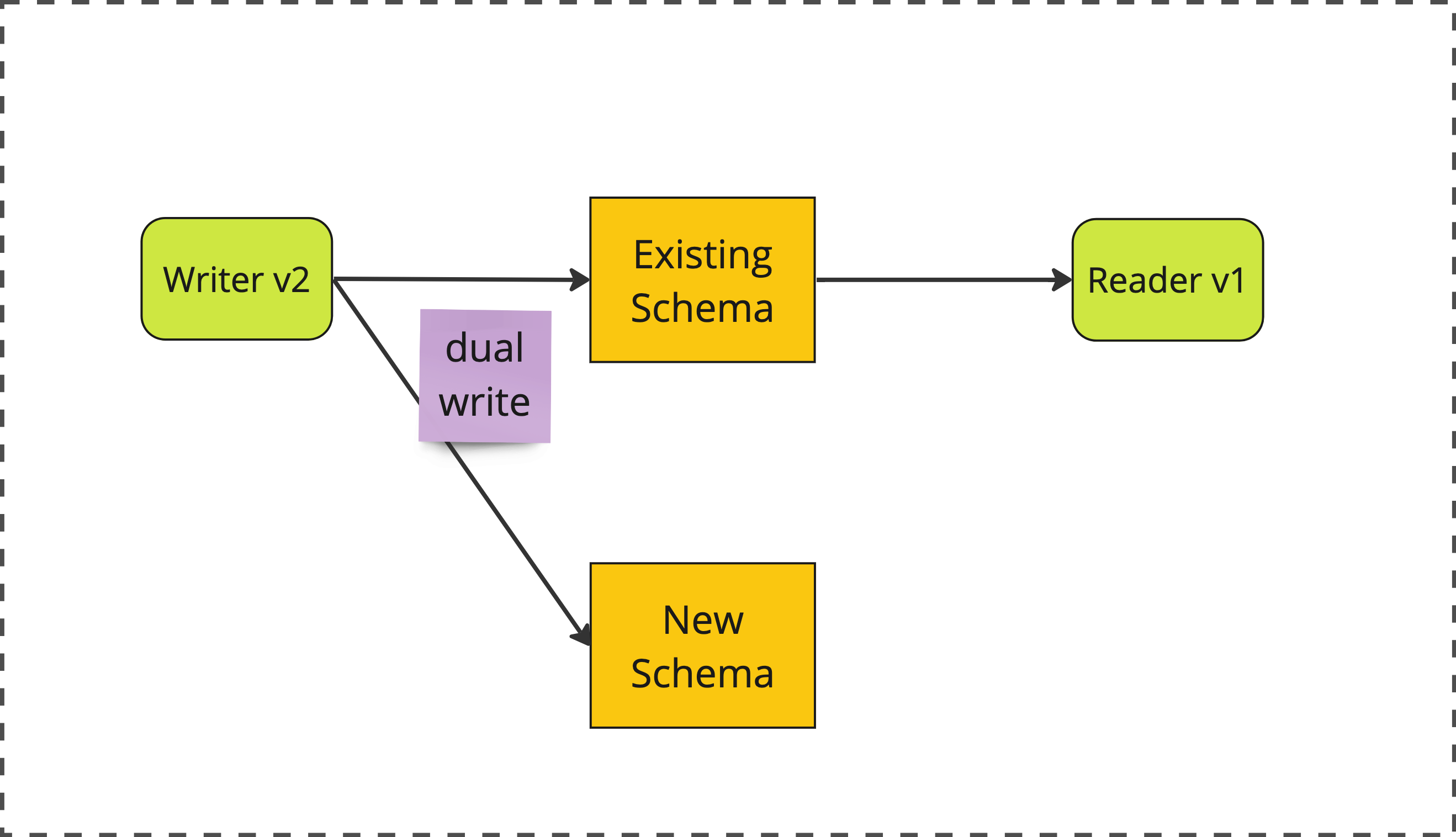
phase 1: expand
In order to do this, we’ll also need to migrate out database schema so that BlogPost contains both an is_published field AND a pub_state field.

expanding the schema to support both fields
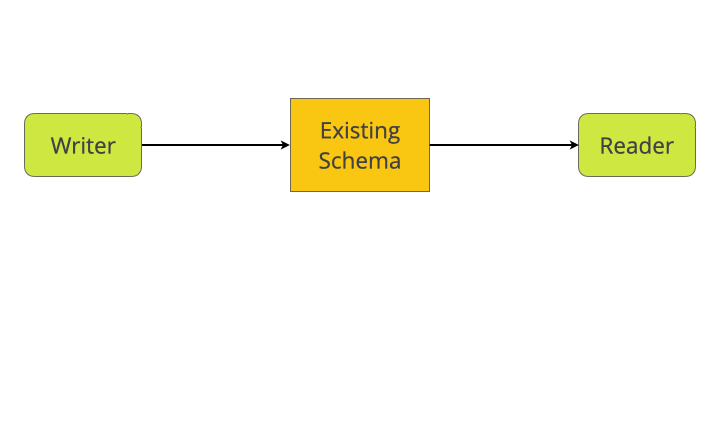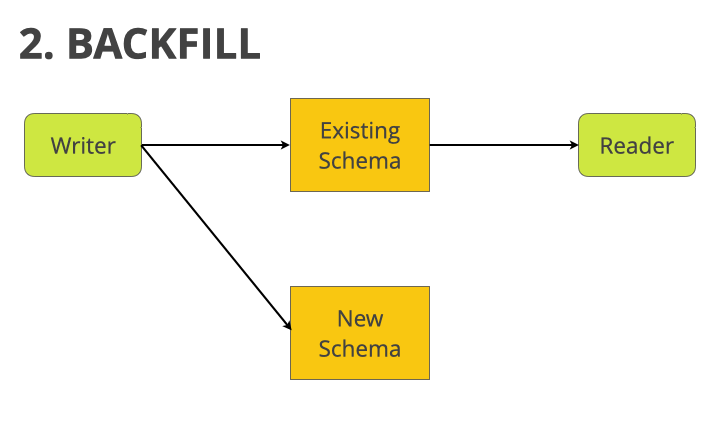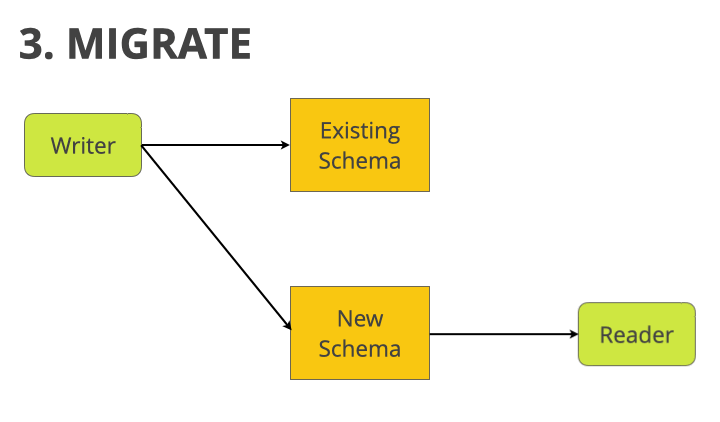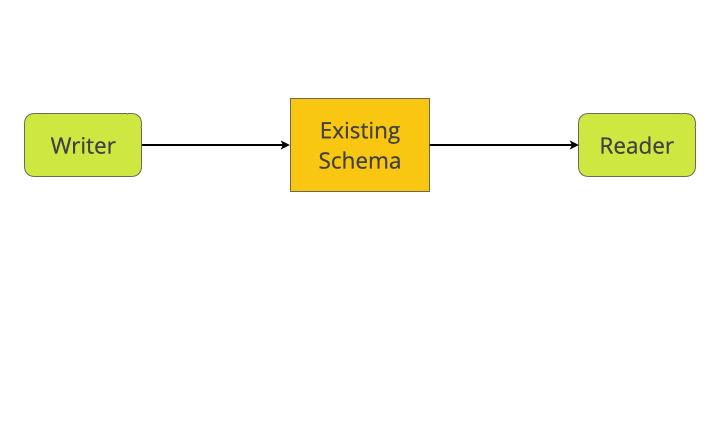
2. Backfill
Next, we perform an out of band data migration to backfill the new pub_state field for all existing BlogPost records, based on the value of the pre-existing is_published field.
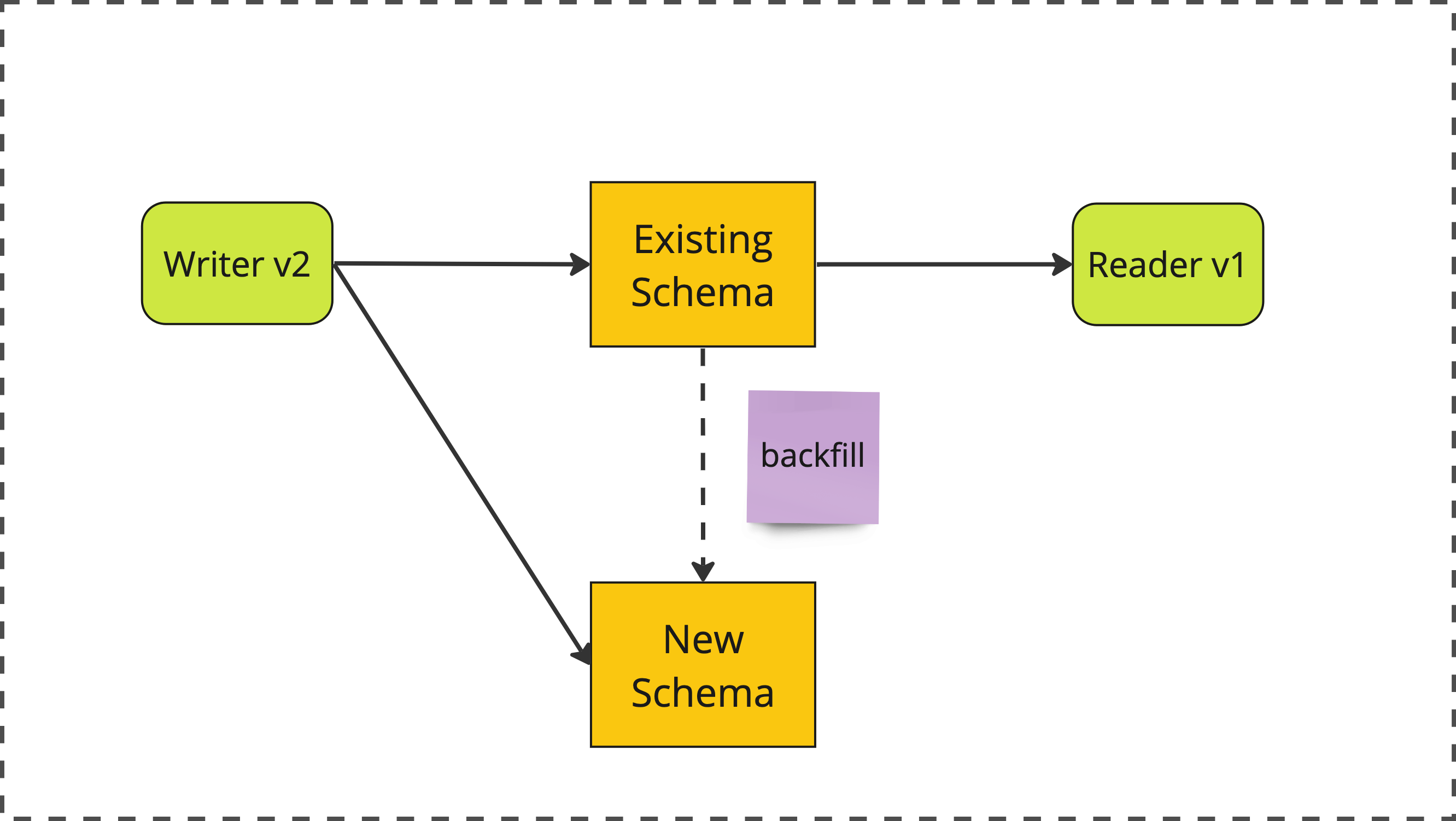
phase 2: backfill
Once this second stage is complete, we can be confident that all existing and future BlogPost records will have correct and consistent values for both is_published and pub_state.
3. Migrate
Next, we update our reader service to read from the new pub_state field, rather than the old is_published field.
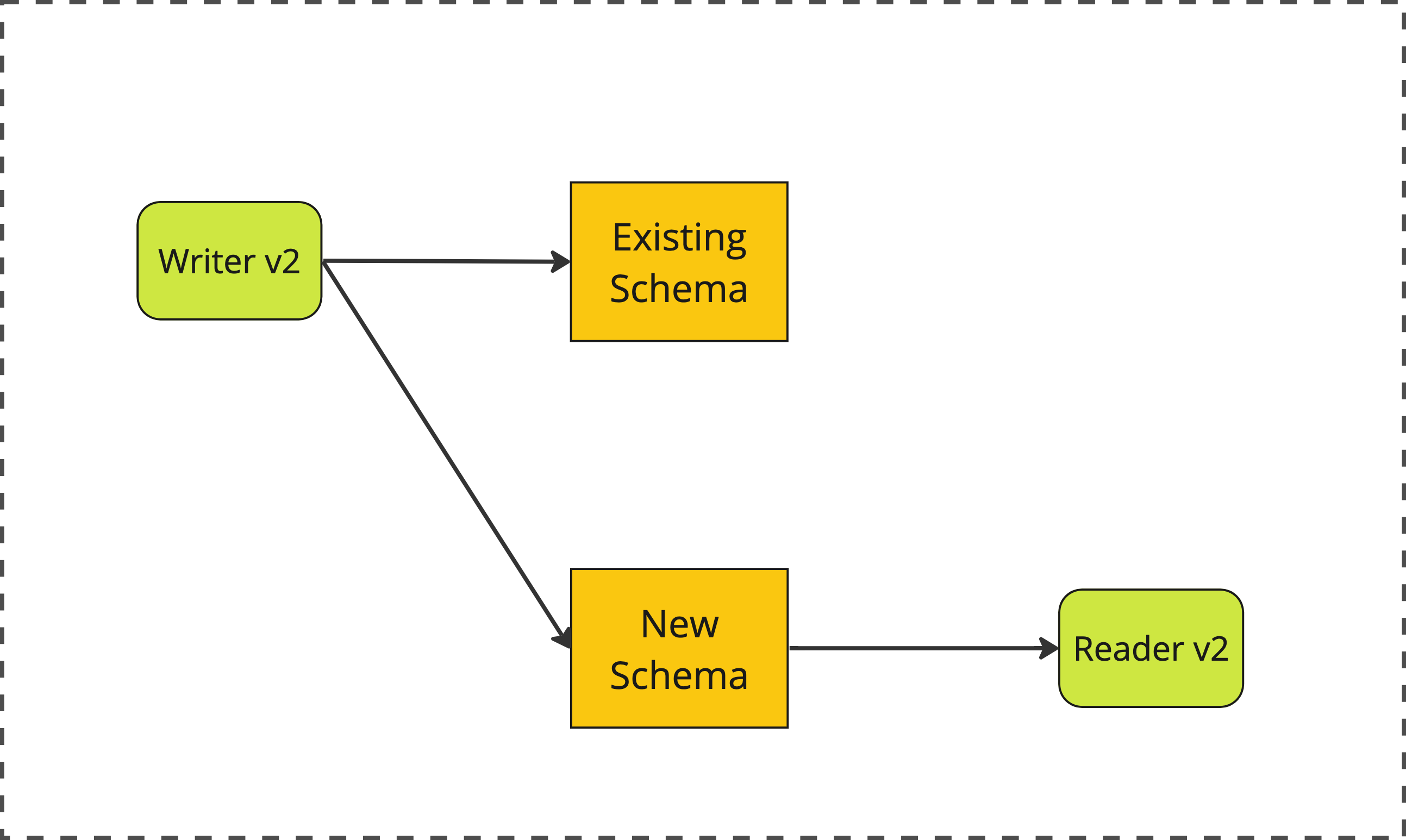
phase 3: migrate
At this point, both reader and writer are using the new schema. All that’s left is to clean up.
4. Contract
Finally, we make a second update to our writer service, removing the dual write and having it just write to the new pub_state field.
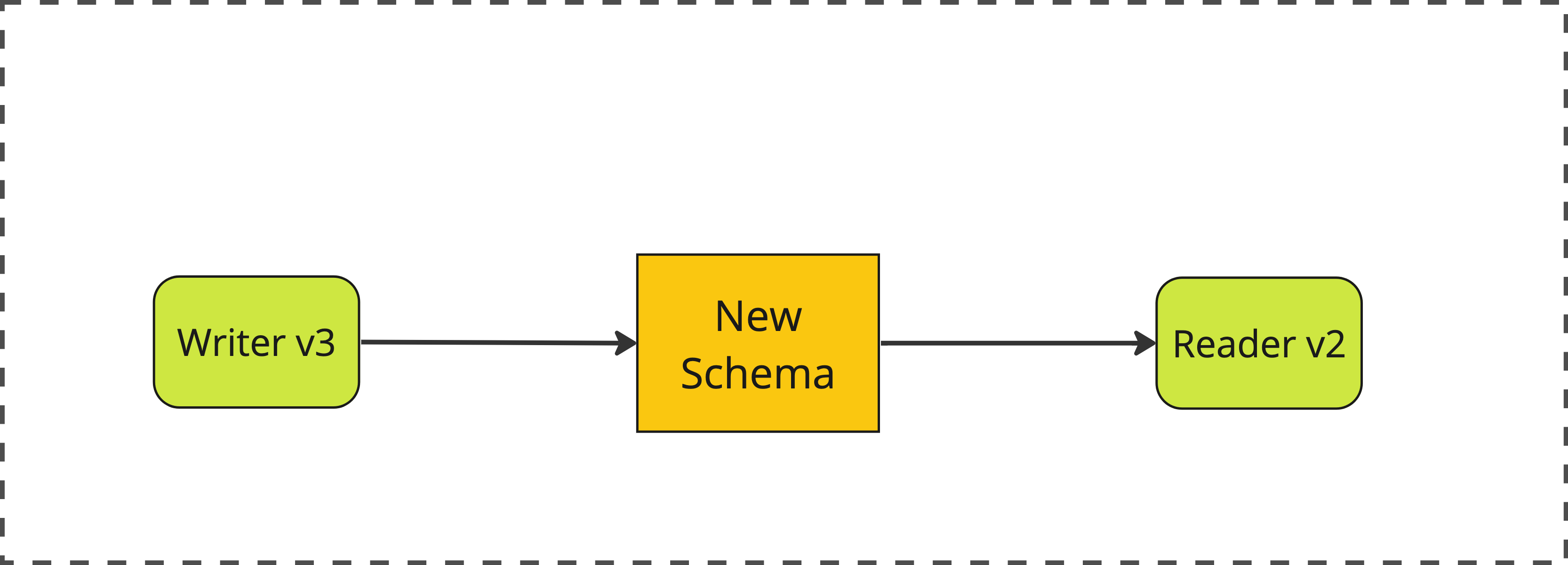
phase 4: contract
We also perform a database schema migration to drop the now fully deprecated is_published field.

contracting the schema to remove the now-unused field
After this stage we have completed our migration!
Why Expand/Contract?
The essential advantage of this multi-staged approach is that each stage is backwards compatible with the previous stage. This allows flexible rollouts, permitting different parts of the system to be at varying release stages without requiring synchronized deployment, ultimately eliminating downtime. Expand/contract is a key enabler for zero-downtime deployments.
Rather than a nerve-wracking big-bang migration we can make a series of small, safe, boring changes at a pace we feel comfortable with.
For larger engineering orgs, anything that reduces the need for coordinated deployments across teams is a huge win. It decouples release schedules and cuts down on painfully expensive cross-team communications.
Additionally, the backwards compatible nature of each change opens up the possibility of using feature flags to control rollout, opening the door to advanced release techniques like dark launching1 and canary releasing. More generally, expand/contract enables branch by abstraction.
What to watch out for
These benefits make expand/contract a preferable approach to a big bang migration in most scenarios, but it’s not a panacea.
don’t let it linger
I’ve seen several teams struggle to see expand/contract migrations all the way through to the contract phase. Typically the external benefit of the migration arrives earlier, and it can be hard to allocate time for the final clean-up work. It’s important to get it done, though - there’s a real cost to carrying around the technical debt of an incomplete expand/contract.
I advise teams to cultivate a habit of performing expand/contracts at as brisk a pace as their deployment schedule allows. A team that is able to deploy to production on demand can get an expand/contract done in an hour or two, with practice. Even a team with a bi-weekly deployment schedule can pull off a full expand/contract migration over the course of a month or two.
not every change requires expand/contract
Knowing that expand/contract provides a safer option for breaking changes, it can be tempting to apply it every time. However, expand/contract is not a freebie - it necessitates a series of coordinated deployments, which take time and require a bit of sustained attention. If you have the option of stopping the world and making a big bang change, then consider taking it!
There’s more to it
At this point you have a good understanding of how expand/contract works, and why it’s superior to a stop-the-world change in many cases. As I’ve explained the basics, I’ve also indicated that there’s more to cover - API migrations vs database migrations, techniques like parallel run and dark launching which allow live testing of a migration, and how Branch By Abstraction enables expand/contract migrations across internal implementations.
If there’s interest, perhaps I’ll write a follow up post to dig into some of those more advanced topics. Let me know!
-
A dark launch of the Expand or Migrate phases can be extended to a more involved pattern called Parallel Run, where you always access both old and new schema in parallel, and compare the results to check for consistency. Sam Newman explains Parallel Run in detail in his book Monolith to Microservices. ↩︎