Why Your AI Coding Assistant Keeps Doing It Wrong, and How To Fix It
May 22, 2025
Current discourse on AI-assisted coding is very polarized. On one side you have the true believers proclaiming “90% of code is going to be written by AI within the next 12 months”. On the other side you have the skeptics dismissing it as a statistical word generator that can’t code anything but trivial greenfield apps.
The “Can AI write good code?” debate is a false dichotomy. It lacks nuance. A much more helpful question is “Which coding tasks is AI good at, and which should be avoided?” People proclaiming “AI-assisted coding is amazing” or “AI-assisted coding is a bust” are mostly talking past each other. If we add some context - “AI-assisted coding is amazing for chores like removing a feature flag” or “AI is a bust for working unsupervised in a large codebase” - we can get to a much more valuable conversation.
What’s more, if we have a more nuanced understanding of the tasks that an AI excels at then we can start shaping our tasks to fit that profile. This lets us reap the productivity boost of AI in a lot more of our day-to-day work - a huge benefit!
In this post we’ll remind ourselves of the unique characteristics of AI coding assistants and map those into a model for how well a coding task plays to the AI’s strengths: the Constraint-Context matrix. Finally, and most importantly, we’ll show you how this lets us reshape our work to better fit the AI’s capabilities.
The goal is to get the AI’s help with more of our dev work, and be happier with the results!
Your new artificial team-member
First, let’s look at what problems AI-assisted coding is a good (and bad) fit for.
As I’ve discussed before, when an LLM is role-playing as a software developer it has a very peculiar set of attributes:
- Writes code at the level of a solid senior engineer - the actual implementation quality is genuinely impressive
- Makes design decisions at the level of a fairly junior engineer - it rarely challenges requirements or suggests alternative approaches
- Weirdly knowledgeable about a very wide range of languages, technologies and libraries - it can work competently in almost any tech stack
- But, it’s their first hour on the team - they know absolutely nothing about your codebase, your coding conventions, your business, your users, your architectural vision, your preferred libraries or tech stack, and so on
- Way too eager to please and impress you - never challenges your ideas, rarely asks any clarifying questions before diving in. Often implements more than what’s needed, loves to violate YAGNI
- Lives very much in the present - just wants to solve the problem directly in front of it, and almost never proactively improves the design of your code
Constraint and Context
Putting these characteristics together, we can start to see which coding tasks this artificial assistant is best suited to help us with.
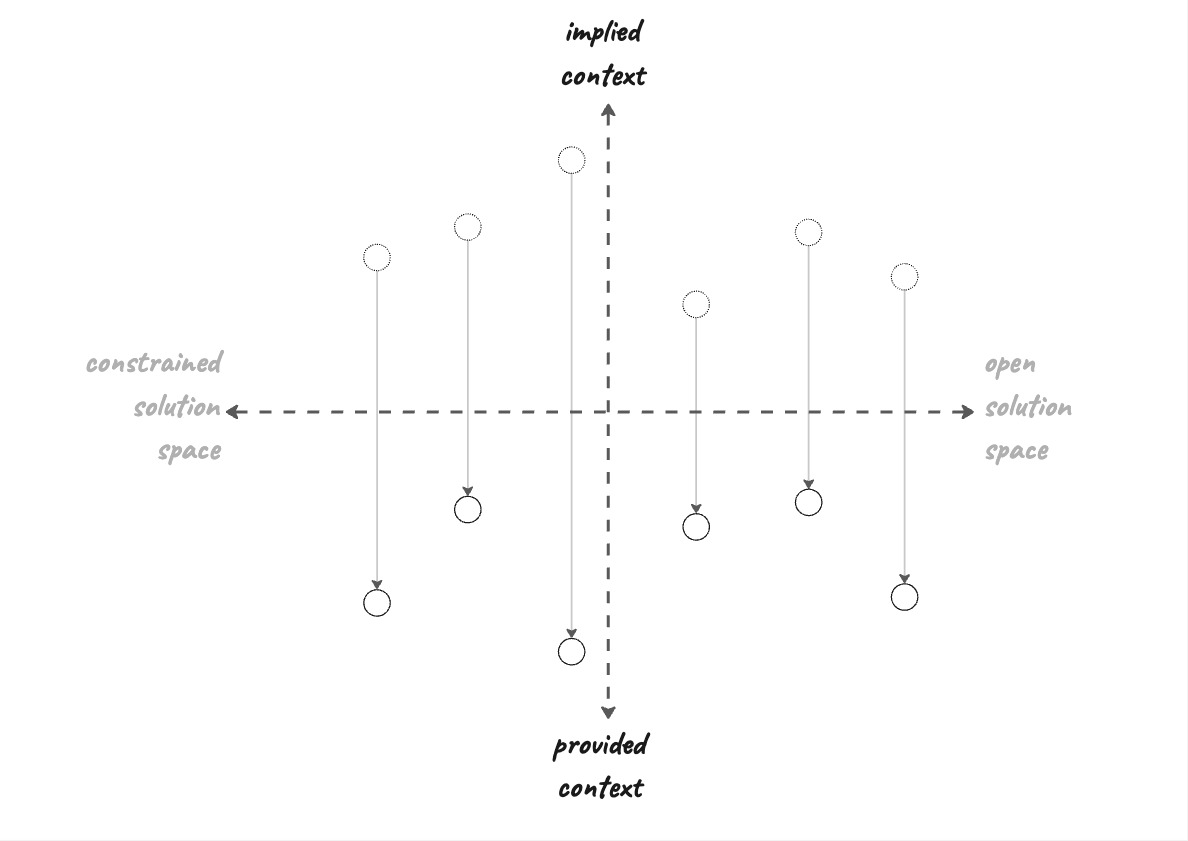
I think about this across two axes: (1) is the solution space constrained or open, and (2) how much **implicit knowledge is required to solve the problem. I call this the Constraint-Context matrix.
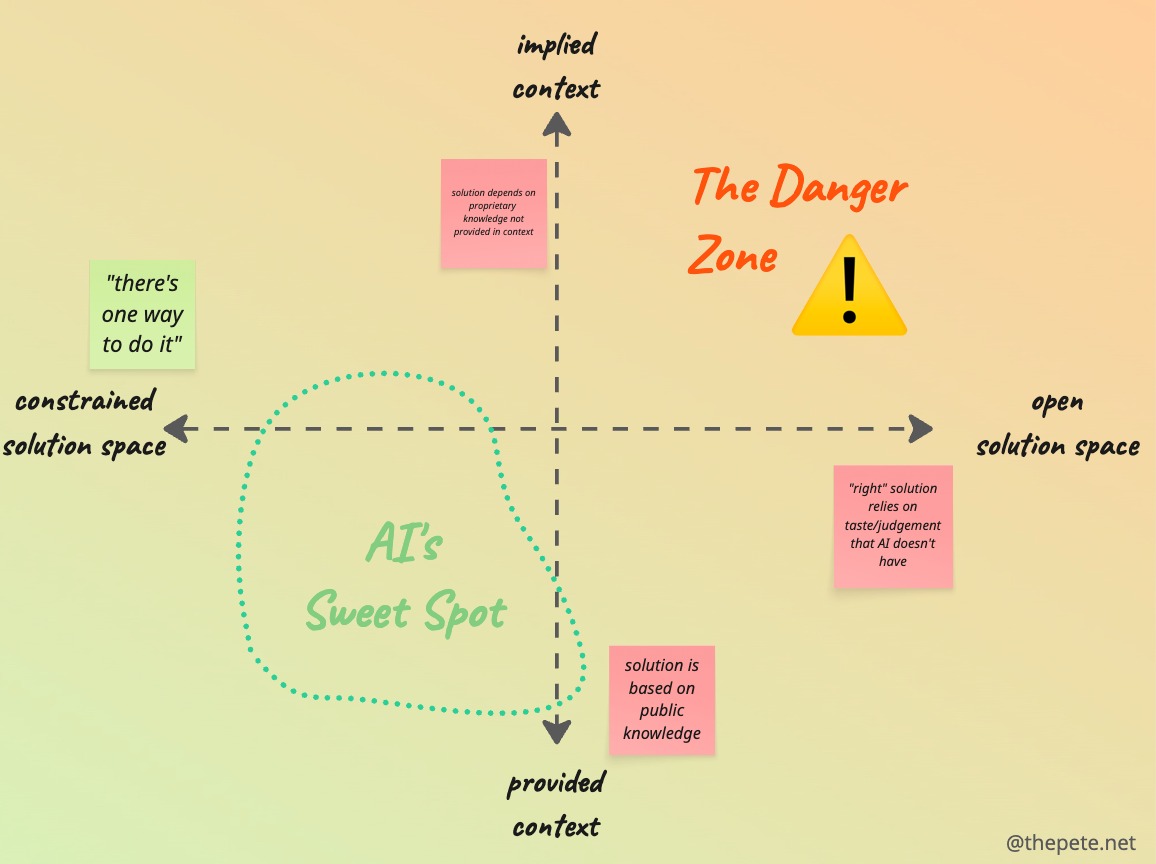
the Constraint-Context matrix
Open vs. closed solution space
The horizontal axis categorizes tasks that have one obvious solution, versus tasks where “it depends” and there’s multiple legitimate ways to solve the problem.
For example, a task like removing a feature flag tends towards the “one obvious solution” side of things: you remove the feature flag check, and you remove the now-deprecated codepath which depended on that feature flag.
On the flip side, a task like “add a way for the user to upload multiple photos at once” is really unconstrained. There are a huge number of ways to implement this, across a variety of dimensions: what should the UX be, what should the API look like, what do we do if some of the uploads fail, do we need to limit overall size or filetype, do we want to use libraries to implement this, and on and on.
When there are many different ways to solve a problem, it’s extremely unlikely that an AI will choose the “right” one, given the AI’s weakness in design thinking that we discussed above. Open solution spaces tend to lead to an AI making disappointing choices. Unless, that is, we give it more context and direction, something we’ll discuss later when we talk about how to shift tasks into a more LLM-friendly space.
Implied vs. provided context
The other major factor to consider when presenting a problem to AI is whether the LLM has all the information it needs. Is it reasonable to expect it to arrive at a good solution based just on information that’s either in the LLM’s public training set or available via its context window.
The state of the art with coding agents today (May 2025) is that every time you start a new chat session your agent is reset to the same knowledge as a brand new hire. That said, it’s a new hire who’s carefully read through all the onboarding material you gave them, and is very good at searching through the codebase in order to gain more context.
Frustratingly, the agent will not learn as it goes, unless you explicitly ask it to add information to its rules/memories. Every time you reset the context or start a new session, you’re working with another brand new hire.
This means that the agent is unlikely to stick to any coding conventions, team practices, or specific architectural principles unless they’re explicitly laid out to the agent. It won’t know which libraries you prefer to use. It won’t know that your team prefers using opentelemetry over logging. It won’t know that there’s already a shared utility for whatever it is trying to achieve.
I’ve found this is often the reason for a coding agent coming up with the “wrong” solution; it simply doesn’t know the conventions that it should be adhering to, and doesn’t have enough context about the existing codebase and architecture.
Moving work into the AI Comfort Zone
Given the above, it might seem that a large majority of coding problems just aren’t a great fit for AI. Happily, that’s not true; we can often adjust our tasks to compensate for the coding agent’s weaknesses.
We can re-structure a problem to make the solution space more constrained, or we can provide additional information to remove the need for implicit context. Often we can do both.
Constraining the solution space
Let’s look at how we can re-frame what we ask an LLM to do so that there’s just one obvious solution.
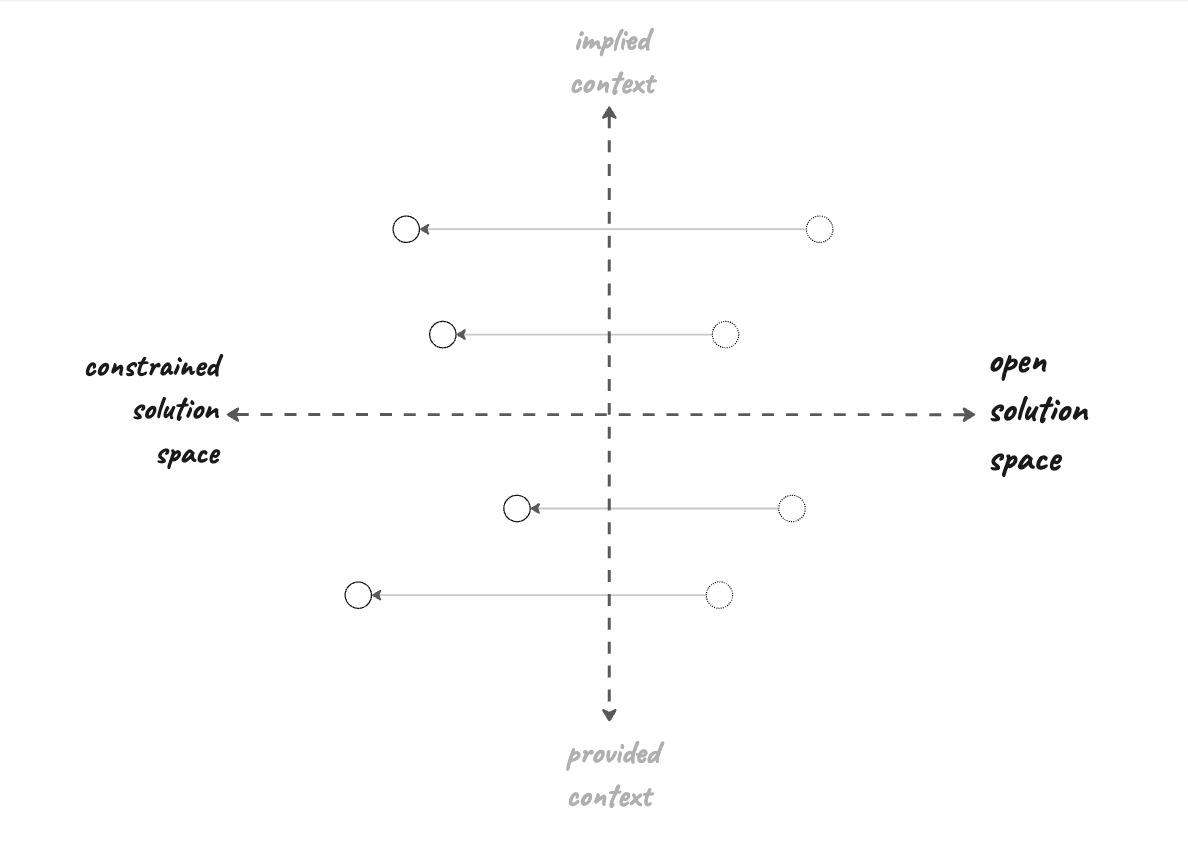
moving tasks towards constrained solutions
Be more directive
Firstly, we can simply be more directive when asking the LLM to solve a problem.
Add directives to your prompt
Rather than prompting:
We need to store first name and last name in separate columns. Please formulate a plan to do so.
you might say
We need to store first name and last name in separate columns. We’ll want to migrate existing data. We’ll also want to use Expand/Contract (each change should be backwards compatible, and we don’t want to take downtime during any deployments).
I often find myself writing the more directive version of a prompt after giving a looser prompt and realizing that I’d left the solution too open-ended.
Break the problem down
Another way to be directive is to break a task down into smaller sub-tasks, and ask the LLM to solve each sub-task separately. This has the effect of constraining the overall shape of the solution, and leaving the LLM to fill in the details.
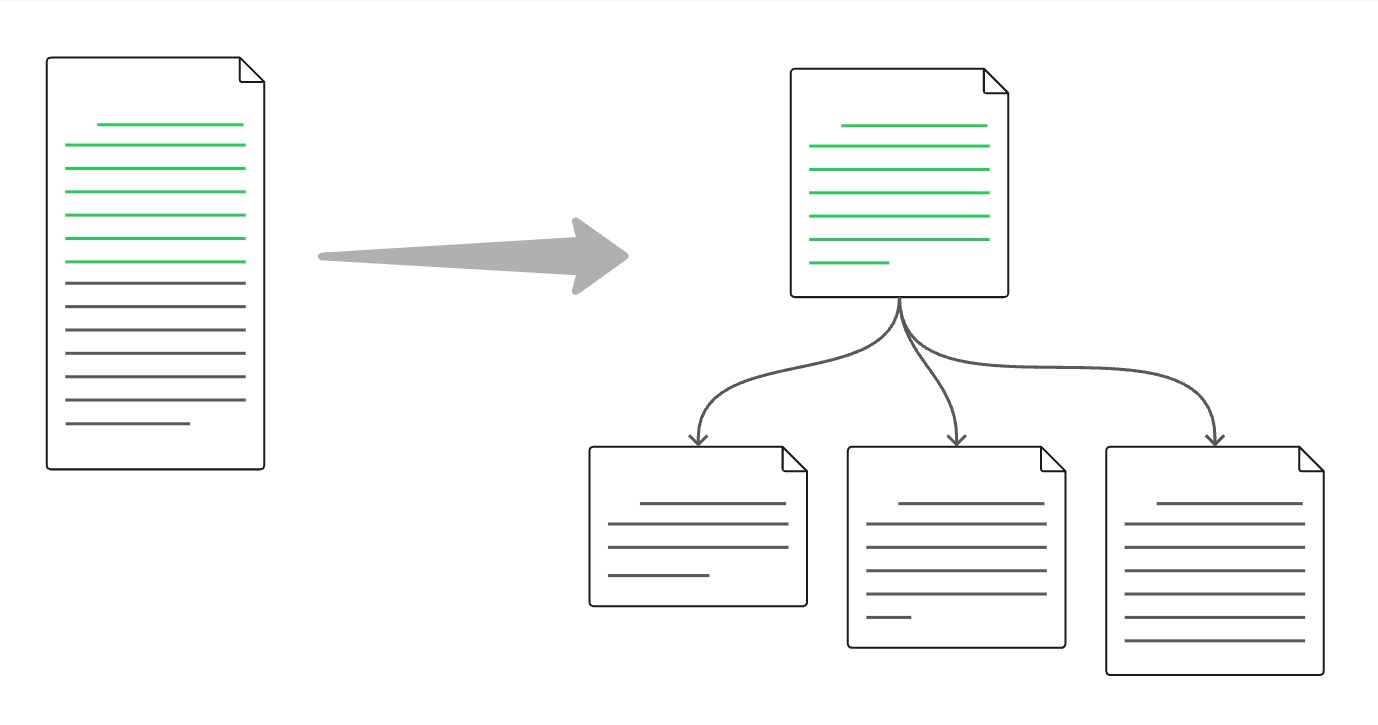
Break problems into smaller sub-tasks
More generally, you can use a workflow like Chain-of-Vibes to turn a big unconstrained problem into a series of smaller problems and put yourself into the decision-making loop. This lets you steer the LLM through an open solution space - it’s doing a lot of the heavy lifting, but you’re still deciding which solution it will head towards.
Providing more context
Often when I find a coding agent picking the “wrong” solution it’s because it doesn’t have all the context that I have. The LLM’s solution space has been left open because it doesn’t have enough context.
We can mitigate this by moving that missing information into the LLM’s context window.
ensure your tasks are solvable with the provided context
A coding agent actually has a variety of mechanisms for building up that context, which means there are a variety of techniques we can use to move from implicit to explicit. Let’s look at them.
Expand the prompt
The simplest way to provide the LLM with more context is to include it in the prompt.
Rather than:
add a caching layer for this operation
you could say:
add a caching layer for this operation. We use redis for caching.
You can also copy-paste entire documents into the prompt:
We’re going to be implementing phase 2 of the following technical design doc. Read the following document carefully and formulate an implementation plan.
[DESIGN DOC CONTENTS]
Embrace memory
All agentic coding tools have a way of adding “rules” or “memory” (e.g. Cursor’s rules, Claude Code’s CLAUDE.md, Windsurf’s memories and rules, ChatGPT’s Saved Memories).
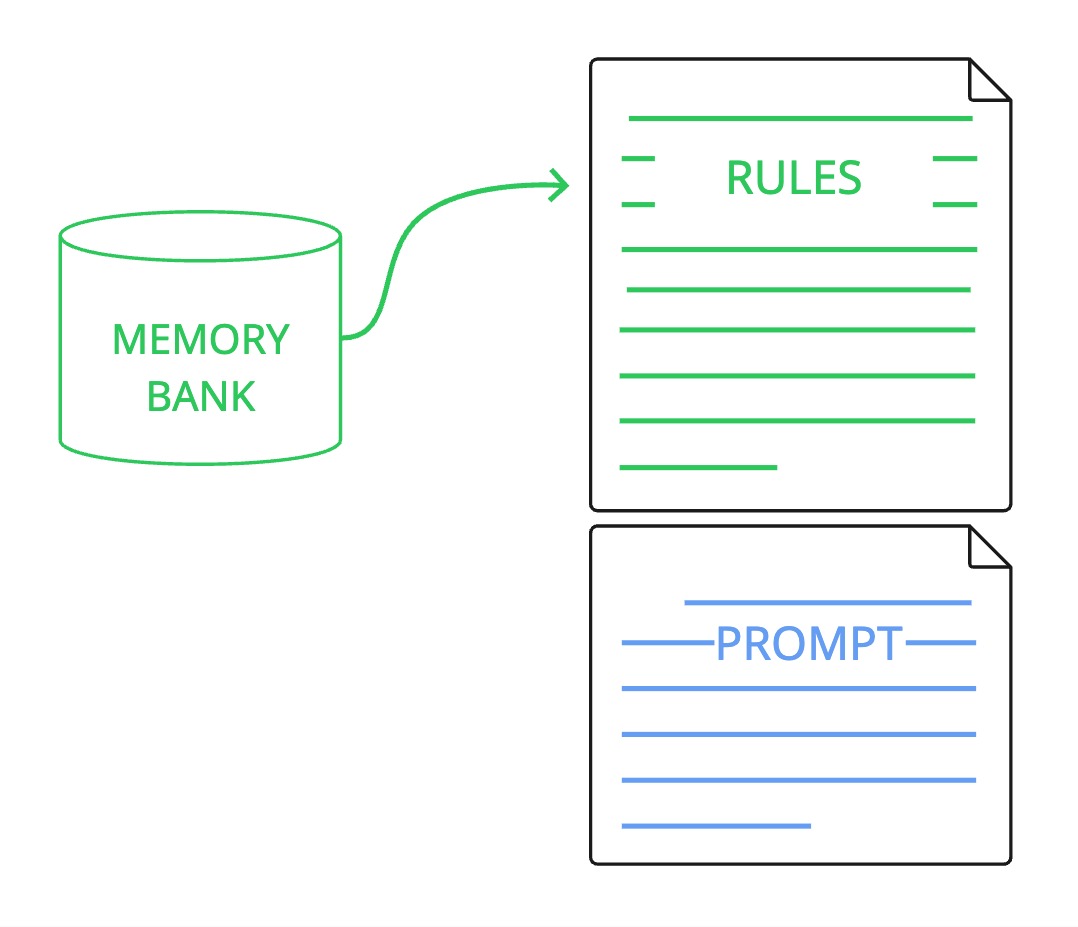
Memory is injected into every prompt
This mechanism is intended specifically as a place to put proprietary information that you always want the LLM to have to hand; things like codebase conventions (e.g. style guides, preferred libraries), how to work within a codebase (e.g. how to run testing and linting tools), as well as general instructions for how the agent should perform its work (e.g. how big should commits be, what tools should the agent try to use).
Think of these as the onboarding materials for an LLM that’s having a permanently recurring first day on the team.
Tools: what make agents magical
Tools are central to the concept of “agentic” AI - the LLM has the ability to use tools, unprompted, in order to load more information into its context window. This is what makes agentic coding assistants so capable/magical - they can seek out the context they need to solve a given task without needing you, the human, to proactively provide everything in the prompt.
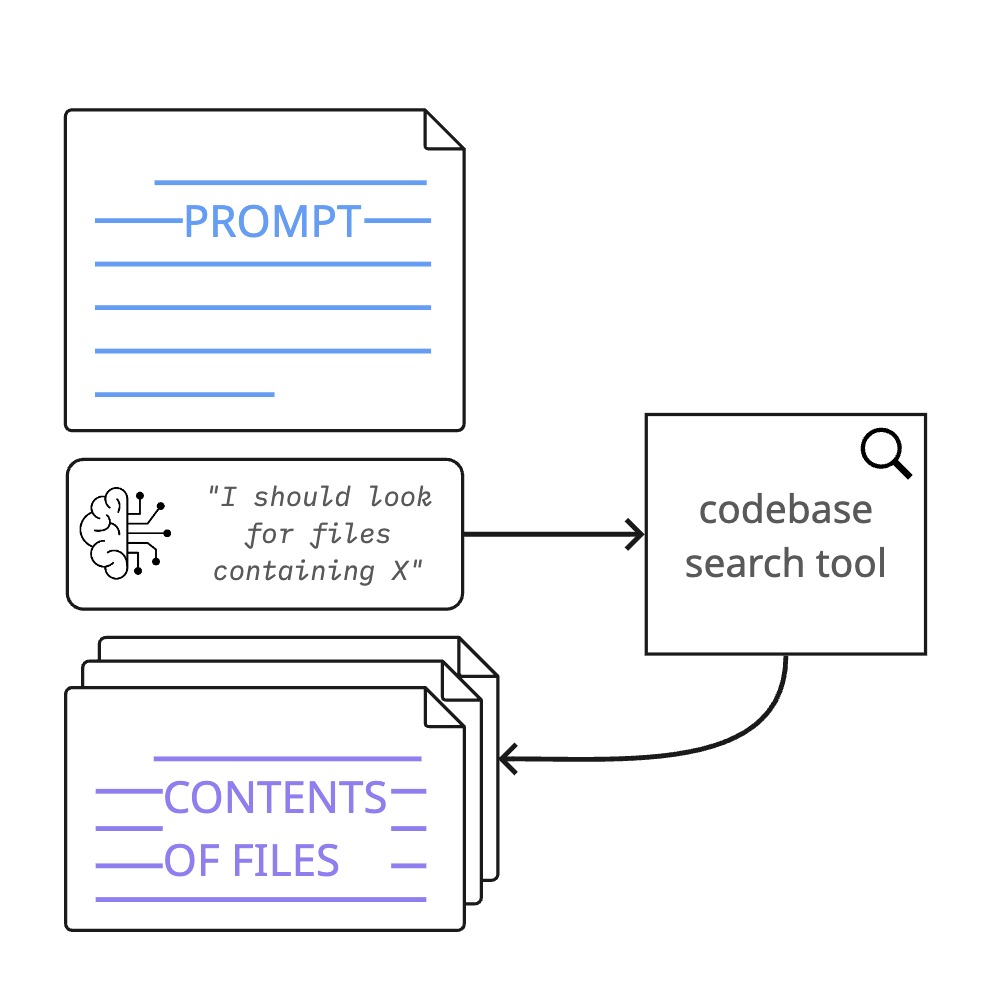
tools add context
In particular, they have tools which can perform efficient search through your codebase, scavenging for context. Regardless of these capabilities, you should still give the LLM hints on where to look (just like you would a new hire).
Rather than a prompt like:
I’d like you to add instrumentation to the engagement update modal
you could say:
I’d like you to add instrumentation to the UpdateAllProjects modal. There’s an existing example in UpdateCompany.
There’s a lot of other ways that tool usage can help an agent gain context. The rise of MCP makes it simple to set up agents with additional sources of context beyond the codebase itself.
For example, if you’ve set up a DB access MCP server then your agent has a way to understand the schema of databases.
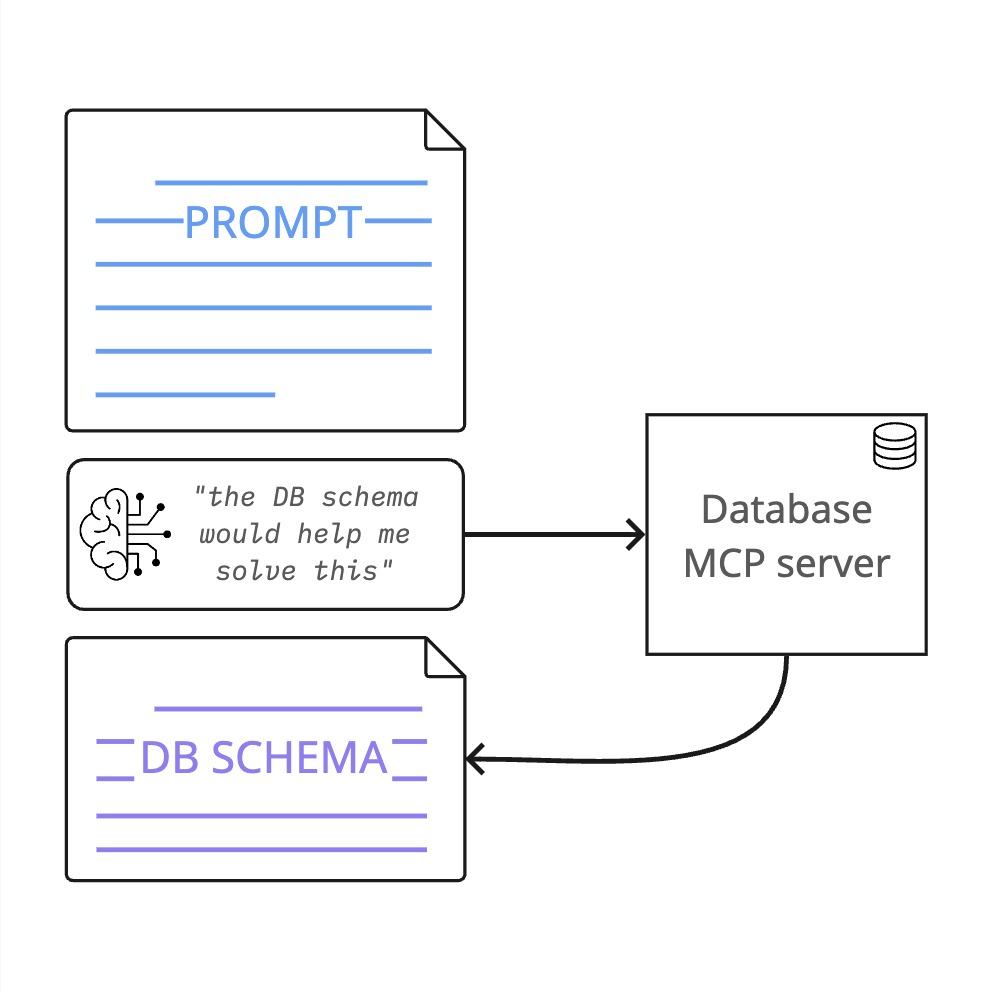
adding the DB schema into context via a tool
Or you can give your agent access to your ticketing system, allowing prompting like:
come up with a plan for implementing ticket SC-15135.
This lets you offload to the agent the boring grunt work of fetching the ticket information from Jira, or Shortcut, or Linear, or whatever.
Reading additional documentation
Coding assistants are also able to use tools to read website documentation, as well as any documentation you have stored in files. This allows the agent to gain extra context by reading library docs, internal documentation, etc.
You can take advantage of this with prompting like:
Optimize the way this database access works. Study the code to understand usage patterns, and be sure to first read the optimization guide https://docs.djangoproject.com/en/5.2/topics/db/optimization/ and QuerySet API https://docs.djangoproject.com/en/5.2/ref/models/querysets/
or:
I want you to implement a caching layer for the ProjectRepository. Read ./docs/ADR-1234 first to understand how we like to implement those.
Under the hood, the agent will use a tool to fetch those web pages - or those local files - and add them to its context window.
Beyond the false dichotomy
Remember the two polarized camps we started with - the true AI believers and the skeptics? They’re both missing the mark. The question isn’t whether an AI can write good code or not. It’s what type of work it’s best at, and how we can move more of that work into the AI’s hands.
This shift in mindset is the key to succeeding with AI. Stop thinking of the LLM as some magical box which can solve every coding problem, and start thinking about how to frame your problems so that they play to the AI’s strengths and avoid its weaknesses.
Your challenge
Next time you consider offloading a task to AI, take a pause and consider the Constraint-Context matrix. How open is the solution space? Does your coding assistant have access to all the context it needs, or am I assuming implicit knowledge.
Then, if you can, re-frame the task to move it into the AI’s comfort zone. Perhaps break it into a Chain of Vibes. Provide more direction in the prompt. Explicitly point the LLM to additional context. Set up an MCP server. Update your rules file with those coding conventions you keep having to repeat.
When you start working with the AI’s capabilities rather than against them, the payoff is immediate. Less time spent undoing the AI’s choices. Less frustration with “dumb” implementations. More successful delegation of the grunt work, freeing you to focus on the interesting problems.
Learn the cheat codes
There’s a lot more to talk about when it comes to improving the performance of coding agents. You should join one of my live workshops, where I dig into the topics in this article, as well as other techniques that unlock a different way of working with AI to build software.
I also offer custom consulting and training for engineering organizations that want to grow and improve AI coding practices: let’s talk!