AI Coding: Managing Context
October 29, 2025
Managing your coding agent’s context is super important.
On the one hand, providing the agent all the relevant information needed to complete it’s task makes it much more likely that it will do what you want it to. Without context the LLM doesn’t know anything about your business, your codebase, or your stylistic preferences. Giving it that context is key in constraining the solution space (lots more about that here.)
On the other hand, irrelevant or incorrect information in the LLM’s context can have a real negative impact on its performance. Effects like Context Rot and Context Poisoning/Distraction are a real thing - this article provides a great summary of the different ways that long contexts can degrade performance.
The problem is that coding agents are constantly accumulating context as a conversation continues - that’s how agents work. And that conversation history contributes a lot more noise to the context than you might think. Besides the actual conversation between you and the agent, the context will also typically contain the full results of every tool call the agent has made so far.
In this article we’ll look at several ways we can keep that cruft in check, keeping your coding agent focused on the current task without distraction.
Managing Context
You can imagine that during a long, wide-ranging coding session the conversation history can easily accumulate a lot of cruft - distracting detail that’s no longer helpful.
To get the most out of your coding agent, you should be actively managing context. Let’s look at the different ways we can do that.
Automatic Summarization
Your agentic coding tool will likely have a mechanism to compact or summarize the conversation history. This can be triggered manually (e.g. /compact in Claude Code, /summarize in Cursor), and many tools will also automatically trigger a summarization once the context size passes some limit.
This works by having an LLM read the existing context and produce an abridged summary of the conversation so far, containing just what it considers the most pertinent information. This summary then replaces the previous conversation.
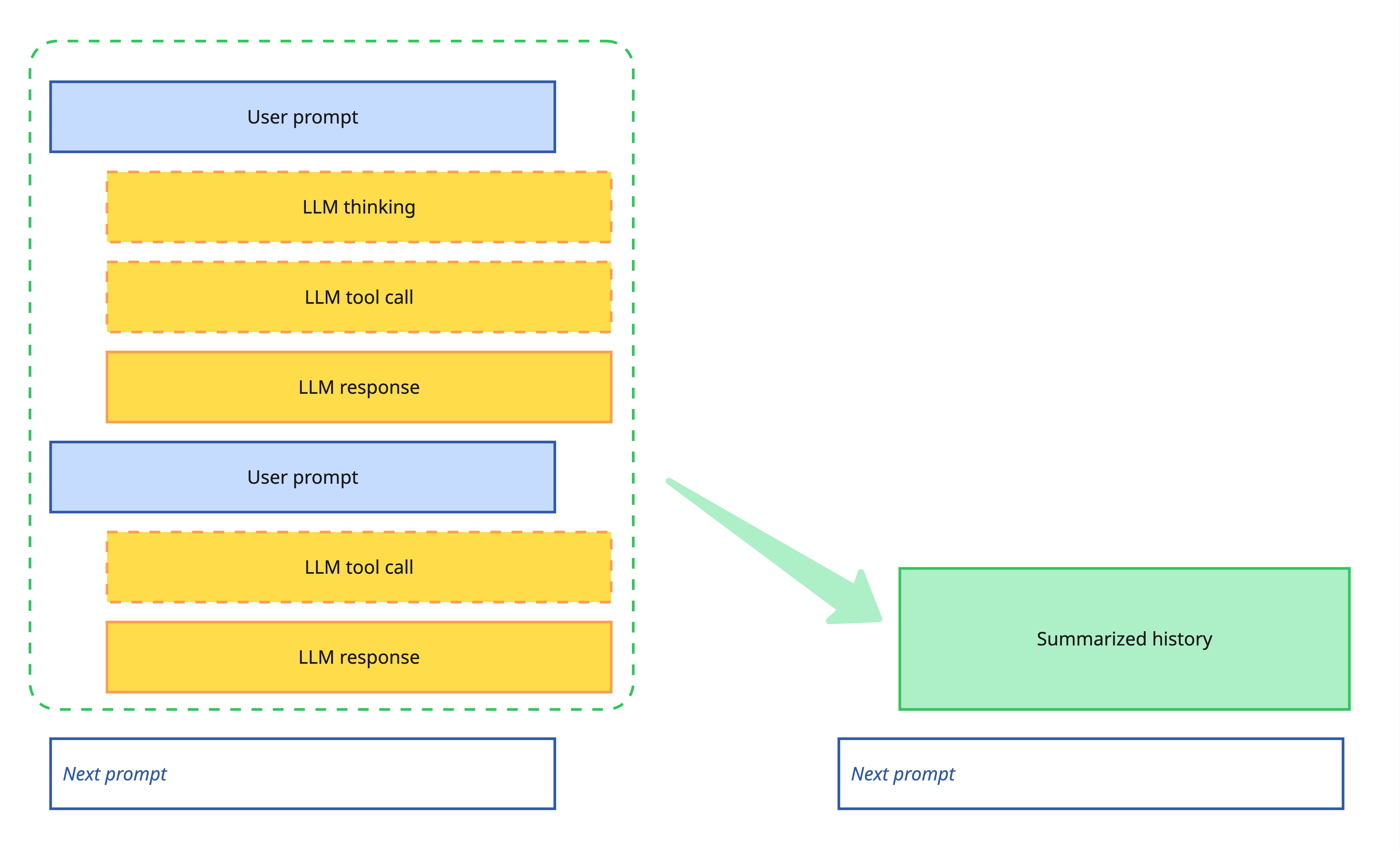
Automatic summarization compacts conversation history
Curated Summarization
The LLM does an OK job at summarization but - as with many things with generative AI - adding a human-in-the-loop can improve performance.
We achieve this by having the LLM produce a summary, but then we review the summary and work with the LLM to further improve it. We remove information that isn’t needed, and ask the LLM to include key details that it initially left out.
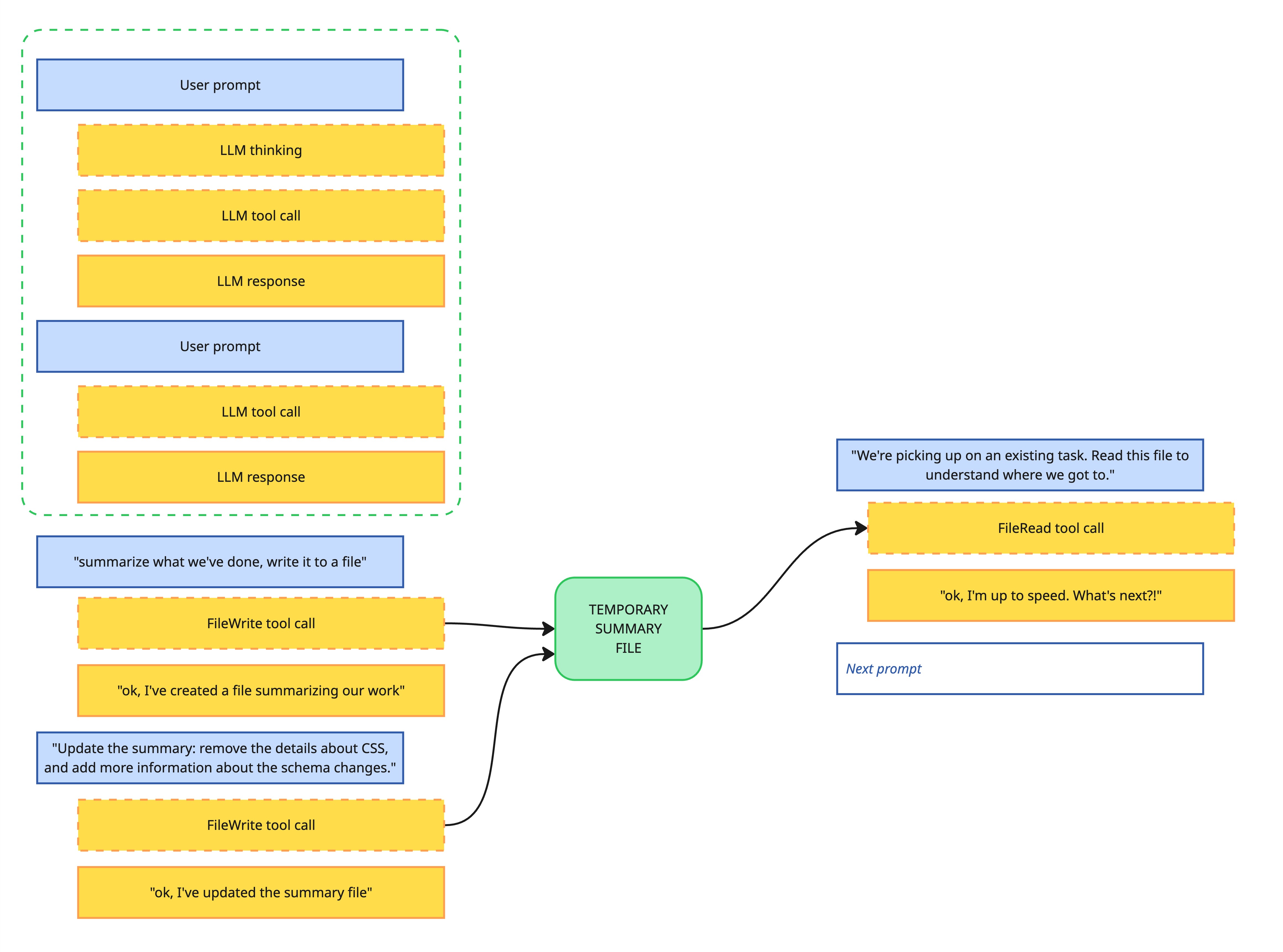
Curated summarization with human-in-the-loop refinement
As far as I’m aware, this human-in-the-loop summarization isn’t a capability that’s built into any agentic coding tools. It’s just a manual process where you ask the LLM to summarize things, then work with the LLM to refine that summary, then copy-paste that summary into a fresh conversation.
I typically do it by adding a prompt like this when a coding session is reaching a natural break point:
It’s time to go home for the day. Another engineer will be picking up this task now. Write a summary of what we’ve worked on in this session, including all information that would be helpful for the engineer who’s taking over from you.
I will typically ask the LLM to write this summary to a temporary file, and then I’ll either manually edit it, or ask the LLM to make changes. Then I’ll start an entirely fresh conversation, with a prompt like:
We’re continuing the work of a fellow engineer. They left a summary in
. Read their summary, then ask any clarifying question before we get started.
Chain-of-Vibes
Context summarization is a way of retroactively dividing a task into a set of somewhat independent steps. As we work we notice a natural breakpoint (or that our conversation history is getting long) and reset the conversation.
Another - I’d argue better - way to approach this is to proactively create a plan which breaks the work up into distinct tasks (optionally assisted by an LLM). We then have a natural context reset every time we move to each new task.
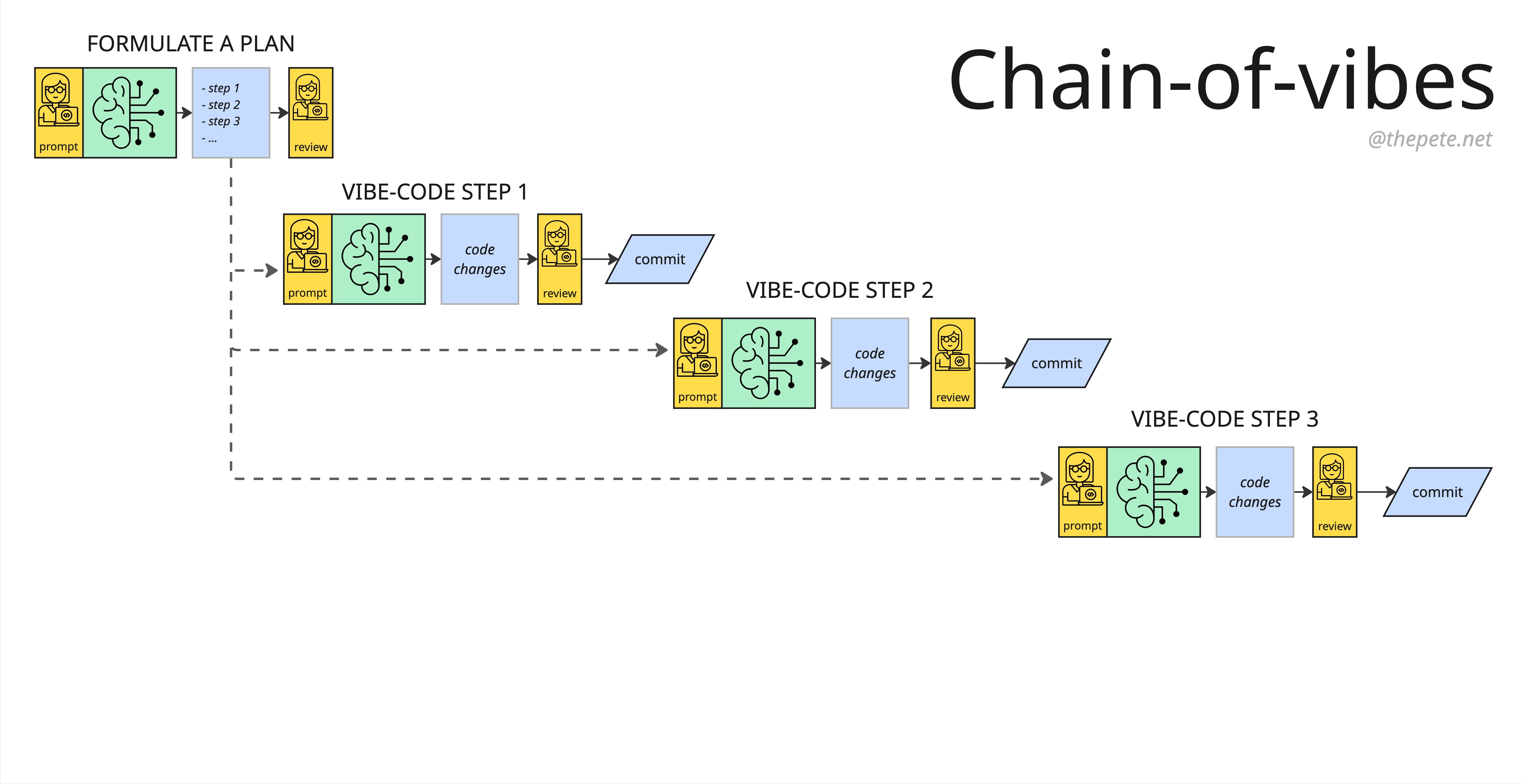
Chain-of-Vibes: Breaking work into discrete tasks with context resets
I call this pattern Chain-of-Vibes, and wrote about it more here.
Sub-contexts
A lot of the value in summarization is in removing the low-level details of tool calls that are only useful for a specific operation but still end up remaining in context.
For example, let’s say that we ask the agent to work with a library, and it starts by looking up the available options for an API call by reading a big web page containing all the documentation for that library. From that point on the information in that web page is not needed, but it is still going to be dragged along in the conversation context. Summarization helps to address this, by pruning those low level details out of the context.
Sub-contexts are another way to deal keep low-level details out of the conversation history, by preventing detailed task information from getting into the agent’s context in the first place. Coding agents achieve that by creating short-lived contexts that are only used for the lifetime of a specific task.
For example, Claude Code has a WebFetch tool which will answer specific questions the agent has about a web page. The agent calls it with a url and a prompt, and it returns just the summarized information, rather than having the main agent read the raw web page (which would leave the entire contents of the web page in the conversation history).
A more general version of this approach is the concept of a sub-agent. This is a general purpose tool that a main agent can use to delegate an entire task to. The task is performed by another agent (a sub-agent) that works within its own context window. The sub-agent does what’s asked in a fully autonomous way, and then returns a summary back to the main agent. The context that the sub-agent used to perform the task is thrown away when the task is complete, rather than being added to the main agent’s context.
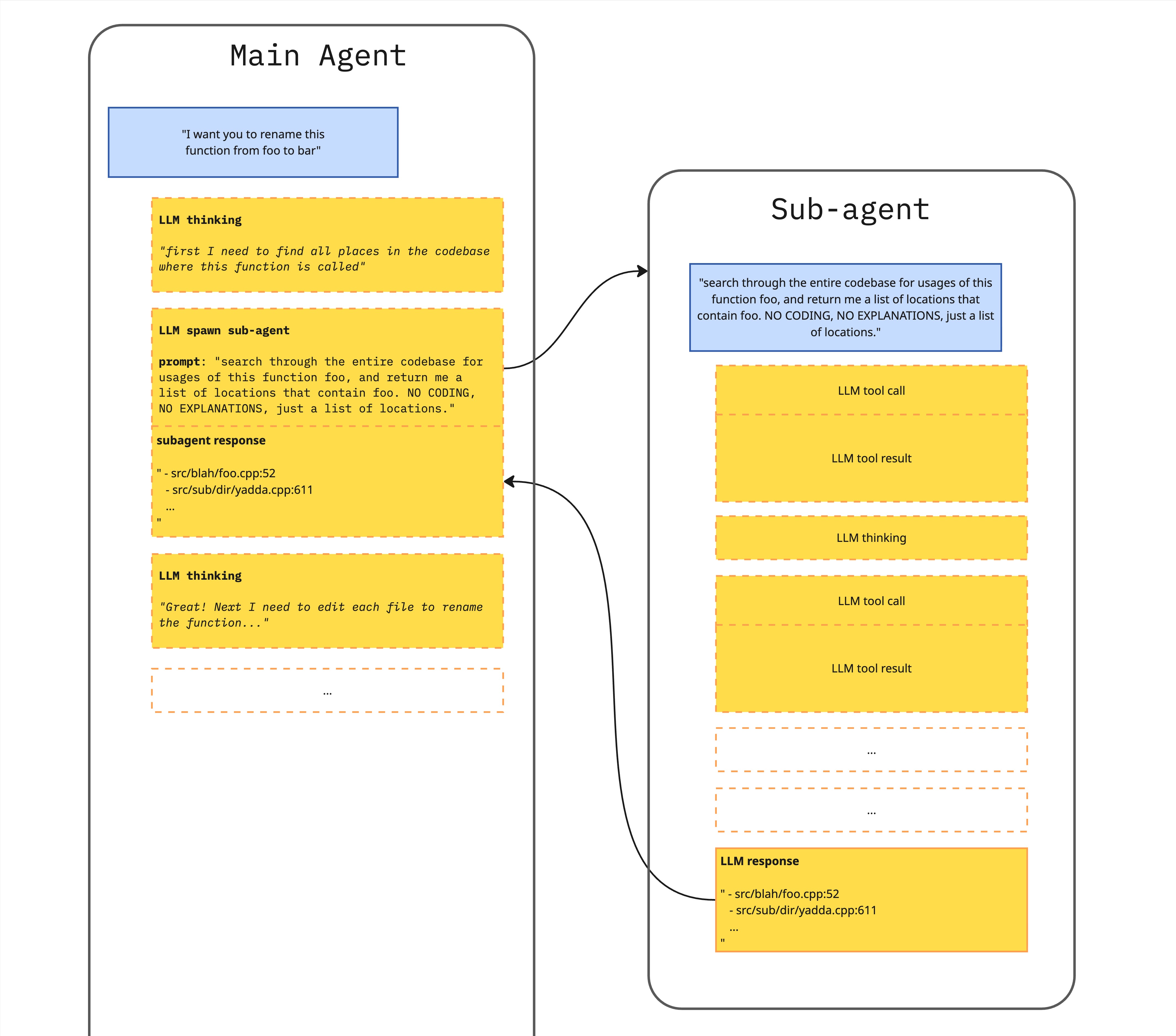
Sub-agents work within their own contexts, return summaries and discard their contexts
If you squint the right way, sub-agents are really the LLM attempting to perform the same type of planning and delegation work that a human is doing in the chain-of-vibes approach. The LLM isn’t as good as a skilled human at this - and possibly never will be - but a lot of times the LLM is good enough, particularly for straightforward coding tasks.
These sub-context patterns are very powerful in terms of managing context, but there’s a risk that useful and relevant information is lost if the sub-agent doesn’t include it in the summary that it returns back to the main agent’s context. This can lead to expensive thrashing as the agent repeatedly performs very similar tasks without gaining helpful context between tasks. Sometimes it’s better to load information into context and have it available for future reference, but the current state-of-the-art agents don’t seem to have a great sense of when to make that call.
There’s more…
These are the main techniques I’m aware of for managing context: summarization, advanced planning, and sub-contexts.
Of course, AI-assisted engineering is evolving FAST - there are some newer tricks that I’ve left out, and probably some brand new approaches I’ve not learned about yet. Let me know!
How big should you let the context get?
So, we know various ways to manage the size of our agent’s context windows. But we haven’t addressed the big question: how big is too big? When should an engineer be telling the agent to summarize? Should we be breaking everything into tiny coding tasks? Should we be having hours-long conversations with our agent?
Honestly, I don’t have a straightforward answer - context management, like many things with AI, is more art than science.
That said, in my experience it’s much better to err on the side of less context than more. Despite the growing size of LLM context windows, various studies have shown a marked dip in LLMs’ ability to keep track of its context long before the context window limit is reached. I prefer to keep each coding session very focused, resetting context whenever the topic switches. That means I need to spend more time with either up-front planning or ad-hoc summarization, but I have found this is a good tradeoff - in my experience the agent seems to perform better when the sessions are short and focused.
What’s very clear to me is that some form of proactive context management is a clear win when it comes to the quality of your coding agent’s work. Don’t expect the tool to do it for you!
Further Reading
I hope this topic has whetted your appetite, and you’re excited to learn more about context engineering. Here are some good places to start:
Effective context engineering for AI agents - Anthropic Engineering
Context Engineering for AI Agents: Lessons from Building Manus - Manus.im
How we built our multi-agent research system - Anthropic Engineering
Advanced Context Engineering for Coding Agents - AI That Works livestream episode #17